
Generarea de seturi de date sintetice pentru RAG
Datele sintetice pentru configurarea RAG
Din păcate, în viața unui inginer de Machine Learning, există adesea o lipsă de date etichetate sau foarte puține dintre acestea. De obicei, după ce realizează aceasta, proiectele încep un proces îndelungat de colectare și etichetare a datelor. Doar după câteva luni se poate începe dezvoltarea unei soluții.
Cu toate acestea, cu apariția LLM-urilor, paradigma s-a schimbat în unele produse: acum se poate conta pe capacitatea de generalizare a LLM-ului și să testezi o idee sau să dezvolți o funcționalitate alimentată de AI aproape imediat. Dacă se dovedește că funcționează (aproape) cum era intenționat, atunci poate începe procesul tradițional de dezvoltare.
 Sursa imaginii: The Rise of the AI Engineer, de S. Wang
Sursa imaginii: The Rise of the AI Engineer, de S. Wang
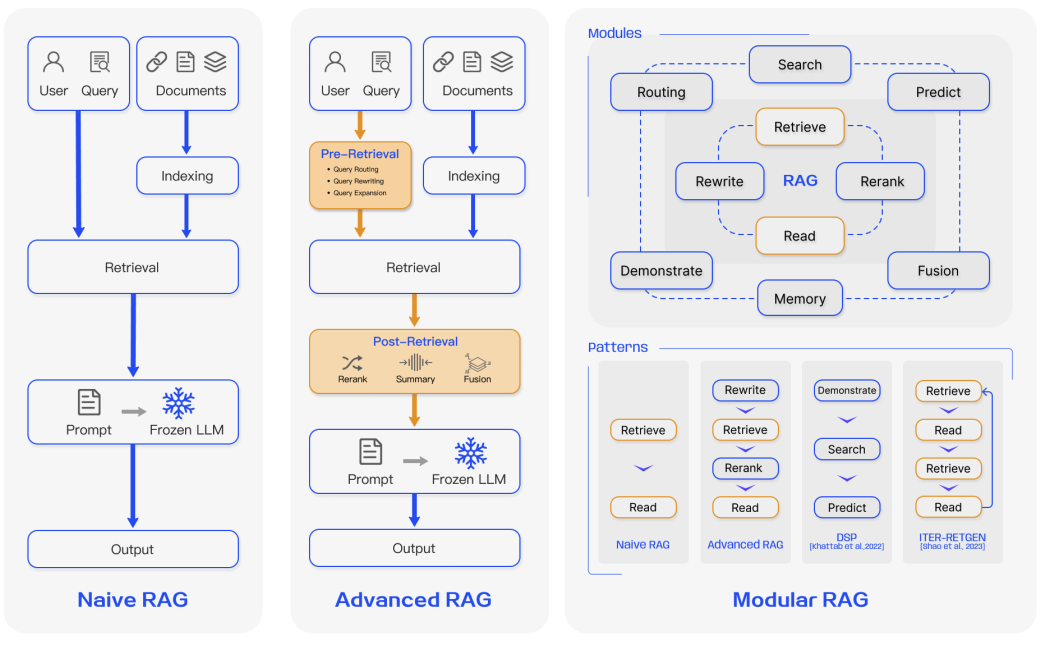
Înțelegerea RAG
Una dintre abordările emergente este Generarea Augmentată de Recuperare (RAG). Este folosită pentru sarcini intensive de cunoștințe unde nu poți conta doar pe cunoștințele modelului. RAG combină o componentă de recuperare a informațiilor cu un model generator de text. Pentru a afla mai multe despre această abordare, consultă secțiunea relevantă din ghid.
Componenta cheie a RAG este un model de Recuperare care identifică documentele relevante și le transmite LLM-ului pentru procesare ulterioară. Cu cât performanța modelului de Recuperare este mai bună, cu atât rezultatul produsului sau funcționalității este mai bun. În mod ideal, Recuperarea funcționează bine din start. Cu toate acestea, performanța sa scade adesea în limbi diferite sau domenii specifice.
Imaginează-ți aceasta: trebuie să creezi un chatbot care să răspundă la întrebări bazându-se pe legile și practicile juridice cehe (în cehă, desigur). Sau să proiectezi un asistent fiscal (un caz de utilizare prezentat de OpenAI în timpul prezentării GPT-4) adaptat pentru piața indiană. Vei găsi probabil că modelul de Recuperare ratează adesea documentele cele mai relevante și nu performează la fel de bine în general, limitând astfel calitatea sistemului.
Dar există o soluție. O tendință emergentă implică folosirea LLM-urilor existente pentru a sintetiza date pentru antrenarea noilor generații de LLM-uri/Recuperatori/alte modele. Acest proces poate fi văzut ca distilarea LLM-urilor în codificatori de dimensiuni standard prin generarea de interogări bazate pe prompturi. Deși distilarea este intensivă din punct de vedere computațional, reduce substanțial costurile de inferență și ar putea îmbunătăți foarte mult performanța, în special în limbile cu resurse reduse sau domeniile specializate.
În acest ghid, ne vom baza pe cele mai recente modele de generare de text, precum ChatGPT și GPT-4, care pot produce cantități vaste de conținut sintetic urmând instrucțiuni. Dai et al. (2022) au propus o metodă unde cu doar 8 exemple etichetate manual și un corpus mare de date neetichetate (documente pentru recuperare, de ex., toate legile analizate), se poate obține o performanță aproape de top. Această cercetare confirmă că datele generate sintetic facilitează antrenarea recuperatorilor specifici sarcinilor pentru sarcini unde fine-tuning-ul supervizat în domeniu este o provocare din cauza lipsei de date.
Generarea seturilor de date specifice domeniului
Pentru a utiliza LLM-ul, trebuie să furnizezi o descriere scurtă și să etichetezi manual câteva exemple. Este important să reții că diferitele sarcini de recuperare posedă intenții de căutare variate, însemnând definiții diferite ale "relevanței". Cu alte cuvinte, pentru aceeași pereche (Interogare, Document), relevanța lor ar putea fi complet diferită bazându-se pe intenția de căutare. De exemplu, o sarcină de recuperare a argumentelor ar putea căuta argumente de susținere, în timp ce alte sarcini necesită contra-argumente (așa cum se vede în setul de date ArguAna).
Consideră exemplul de mai jos. Deși scris în engleză pentru o înțelegere mai ușoară, reține că datele pot fi în orice limbă deoarece ChatGPT/GPT-4 procesează eficient chiar și limbile cu resurse reduse.
Exemplu de prompt
Sarcina: Identifică un contra-argument pentru argumentul dat.
Argumentul #1: {inserează pasajul X1 aici}
O interogare concisă de contra-argument legată de argumentul #1: {inserează interogarea Y1 pregătită manual aici}
Argumentul #2: {inserează pasajul X2 aici}
O interogare concisă de contra-argument legată de argumentul #2: {inserează interogarea Y2 pregătită manual aici}
<- lipește exemplele tale aici ->
Argumentul N: Chiar dacă o amendă este făcută proporțională cu venitul, nu vei obține egalitatea de impact pe care o dorești. Aceasta se datorează faptului că impactul nu este proporțional simplu cu venitul, ci trebuie să ia în considerare o serie de alți factori. De exemplu, cineva care susține o familie va înfrunta un impact mai mare decât cineva care nu o face, deoarece au un venit disponibil mai mic. În plus, o amendă bazată pe venit ignoră bogăția generală (adică cât de mult bani are cineva de fapt: cineva ar putea avea multe active dar să nu aibă un venit mare). Propoziția nu ține cont de aceste inegalități, care ar putea avea un efect de înclinare mult mai mare, și prin urmare argumentul este aplicat inconsistent.
O interogare concisă de contra-argument legată de argumentul #N:Ieșirea generată
pedeapsa casei ar face amenzile relative venituluiFormularea matematică
În general, un astfel de prompt poate fi exprimat ca:
(e_prompt, e_doc(d1), e_query(q1), ..., e_doc(dk), e_query(qk), e_doc(d))Unde:
e_docșie_querysunt descrieri specifice sarcinii pentru document, respectiv interogaree_prompteste un prompt/instrucțiune specifică sarcinii pentru ChatGPT/GPT-4deste un document nou, pentru care LLM-ul va genera o interogare
Din acest prompt, doar ultimul document d și interogarea generată vor fi folosite pentru antrenarea ulterioară a modelului local. Această abordare poate fi aplicată când un corpus de recuperare țintă D este disponibil, dar numărul de perechi interogare-document anotate pentru noua sarcină este limitat.
Privire de ansamblu asupra pipeline-ului
Sursa imaginii: Dai et al. (2022)
Cele mai bune practici
Este crucial să gestionezi anotarea manuală a exemplelor în mod responsabil. Este mai bine să pregătești mai multe (de exemplu, 20) și să alegi aleator 2-8 dintre ele pentru prompt. Aceasta crește diversitatea datelor generate fără costuri semnificative de timp în anotare. Cu toate acestea, aceste exemple ar trebui să fie:
- Reprezentative pentru domeniul țintă
- Formatate corect conform specificațiilor
- Detaliate cu specificații precum lungimea interogării țintă sau tonul
Cu cât exemplele și instrucțiunile sunt mai precise, cu atât datele sintetice vor fi mai bune pentru antrenarea Recuperatorului. Exemplele de câteva exemple de calitate scăzută pot avea un impact negativ asupra calității rezultate a modelului antrenat.
Analiza costurilor
În majoritatea cazurilor, folosirea unui model mai accesibil precum ChatGPT este suficientă, deoarece performează bine cu domenii neobișnuite și limbi diferite de engleză.
Exemplu de calcul al costului:
- Un prompt cu instrucțiuni și 4-5 exemple ocupă de obicei 700 de tokeni (presupunând că fiecare pasaj nu este mai lung de 128 de tokeni din cauza constrângerilor Recuperatorului)
- Generarea este de 25 de tokeni
- Costul pentru 50.000 de documente:
50.000 * (700 * 0.001 * $0.0015 + 25 * 0.001 * $0.002) = $55 - Unde
$0.0015și$0.002sunt costul per 1.000 de tokeni în API-ul GPT-3.5 Turbo
Este chiar posibil să generezi 2-4 exemple de interogare pentru același document. Cu toate acestea, adesea beneficiile antrenării ulterioare merită, în special dacă folosești Recuperatorul nu pentru un domeniu general (precum recuperarea de știri în engleză) ci pentru unul specific (precum legile cehe, așa cum s-a menționat).
Impactul și beneficiile
Cifra de 50.000 nu este aleatorie. În cercetarea lui Dai et al. (2022), se afirmă că aceasta este aproximativ numărul de date etichetate manual necesare pentru ca un model să se potrivească cu calitatea unuia antrenat pe date sintetice.
Abordarea tradițională:
- Colectează cel puțin 10.000 de exemple înainte de a-ți lansa produsul
- Durează nu mai puțin de o lună
- Costurile cu forța de muncă ar depăși cu siguranță o mie de dolari
Abordarea cu date sintetice:
- Obține creșteri cu două cifre ale metricilor în doar câteva zile
- Cost: ~$55 pentru 50.000 de exemple sintetice