
Llama 3
Prezentare generală
Meta a introdus recent noua lor familie de modele de limbaj mari (LLM-uri) numită Llama 3. Această lansare include modele 8B și 70B de parametri pre-antrenate și fine-tunate pentru instrucțiuni.
Detaliile arhitecturii Llama 3
Iată un rezumat al detaliilor tehnice menționate ale Llama 3:
Arhitectura de bază
- Tip: Transformer decoder standard
- Vocabularul: 128K tokeni
- Lungimea secvenței: 8K tokeni
- Mecanismul de atenție: Atenția grouped query (GQA)
Detaliile antrenamentului
- Pre-antrenament: Peste 15T tokeni
- Post-antrenament: Combinația de SFT, rejection sampling, PPO și DPO
Performanța
Comparările modelelor
Llama 3 8B
Llama 3 8B (fine-tunat pentru instrucțiuni) depășește:
- Gemma 7B
- Mistral 7B Instruct
Llama 3 70B
Llama 3 70B depășește în general:
- Gemini Pro 1.5
- Claude 3 Sonnet
Notă: Rămâne puțin în urmă pe benchmark-ul MATH când este comparat cu Gemini Pro 1.5.
Rezultatele pe benchmark-uri
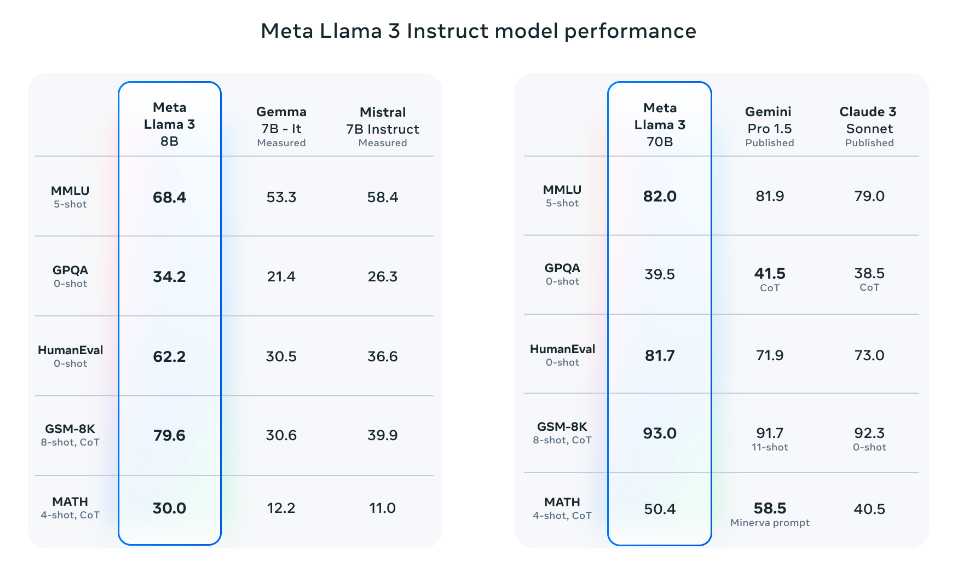
Sursa: Meta AI
Performanța modelului pre-antrenat
Modelele pre-antrenate depășesc, de asemenea, alte modele pe mai multe benchmark-uri:
- AGIEval (Engleză)
- MMLU
- Big-Bench Hard
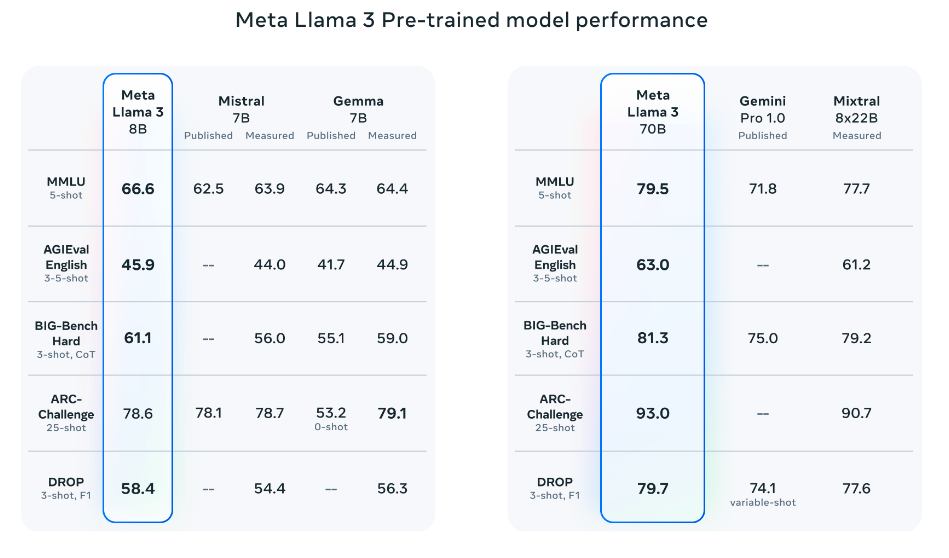
Sursa: Meta AI
Llama 3 400B
Lansarea viitoare
Meta a raportat, de asemenea, că vor lansa un model de 400B de parametri care este încă în antrenament și vine în curând!
Funcționalitățile planificate
Există, de asemenea, eforturi în jurul:
- Suportului multimodal
- Capacităților multilingve
- Ferestrelor de context mai lungi
Performanța actuală
Checkpoint-ul actual pentru Llama 3 400B (din 15 aprilie 2024) produce următoarele rezultate pe benchmark-urile comune precum MMLU și Big-Bench Hard:
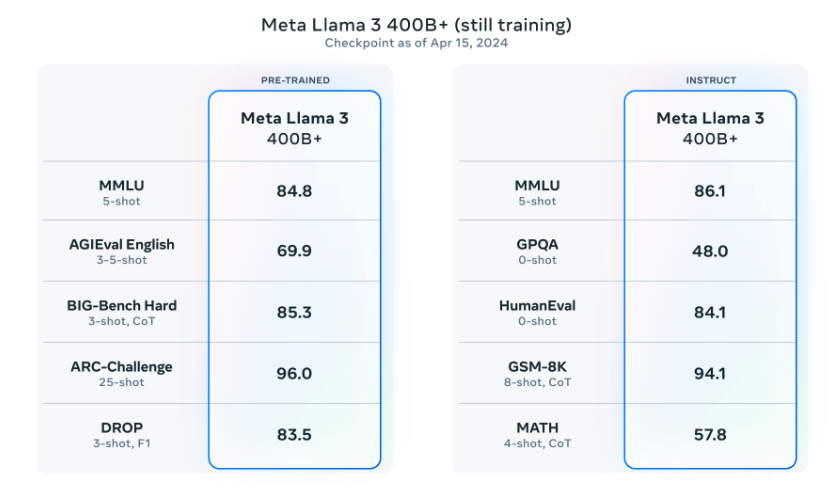
Sursa: Meta AI
Licențierea
Informațiile de licențiere pentru modelele Llama 3 pot fi găsite pe model card.
Recenzia extinsă a Llama 3
Iată o recenzie mai lungă a Llama 3:
[Conținutul recenziei extinse ar merge aici]
Învățăminte cheie
- Lansarea duală de modele: Variantele de 8B și 70B de parametri disponibile
- Performanță puternică: Depășește Gemma 7B, Mistral 7B Instruct și competă cu Gemini Pro 1.5
- Arhitectura avansată: Folosește atenia grouped query și tehnici extensive de post-antrenament
- Scala masivă: Model de 400B de parametri în dezvoltare
- Capacitățile viitoare: Multimodal, multilingv și context extins planificate
- Accesul deschis: Disponibil pentru utilizarea în cercetare și dezvoltare