
Promptarea multimodală CoT
Prezentare generală
Zhang et al. (2023) au propus recent o abordare multimodală de promptare chain-of-thought. CoT tradițional se concentrează pe modalitatea lingvistică. În contrast, CoT multimodal încorporează textul și viziunea într-un cadru în două etape. Primul pas implică generarea raționamentului bazat pe informații multimodale. Aceasta este urmată de a doua fază, inferența răspunsului, care valorifică raționamentele informative generate.
Inovația cheie
Modelul multimodal CoT (1B) depășește GPT-3.5 pe benchmark-ul ScienceQA.
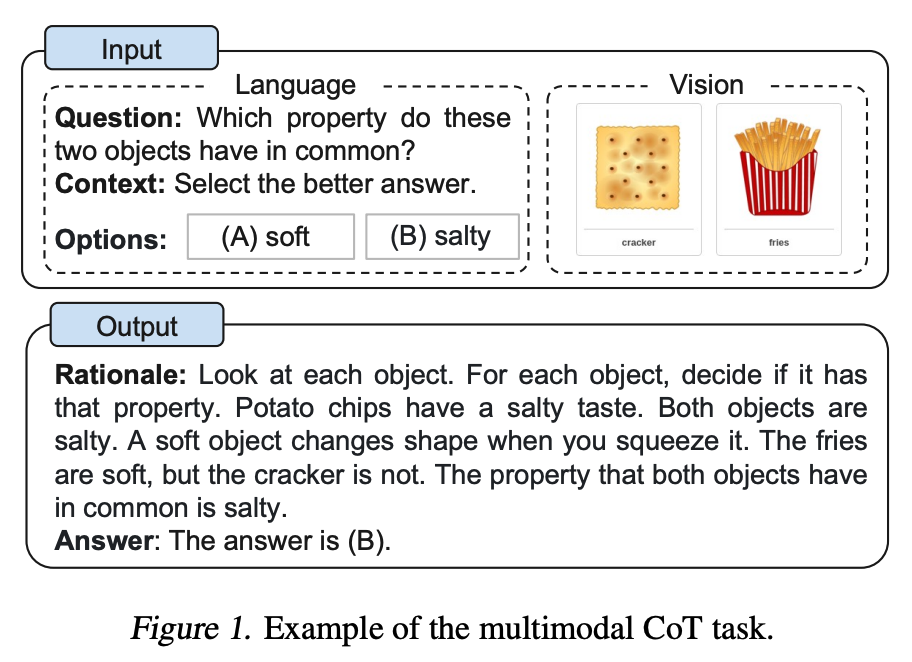
Sursa imaginii: Zhang et al. (2023)
Cum funcționează
CoT multimodal extinde promptarea tradițională chain-of-thought prin:
- Procesarea intrării multimodale: Combină informațiile text și vizuale
- Cadrul în două etape:
- Etapa 1: Generează raționamentul bazat pe contextul multimodal
- Etapa 2: Inferă răspunsurile folosind raționamentele generate
- Raționamentul îmbunătățit: Valorifică indicii vizuale pentru o înțelegere mai bună
Aplicații
- Răspunsurile la întrebări vizuale: Răspunsurile la întrebări despre imagini
- Educația științifică: Explicarea conceptelor științifice cu diagrame
- Analiza documentelor: Înțelegerea documentelor cu elemente vizuale
- Raționamentul multimodal: Sarcini care necesită atât înțelegerea textului cât și vizuală
Beneficii cheie
- Înțelegerea multimodală: Procesează atât informațiile text cât și vizuale
- Raționamentul îmbunătățit: Raționament mai bun prin contextul vizual
- Performanța îmbunătățită: Depășește modelele doar text pe sarcinile vizuale
- Aplicațiile educaționale: Eficiente pentru explicarea conceptelor vizuale
Subiecte conexe
- Promptarea Chain-of-Thought - Înțelegerea tehnicilor de promptare CoT
- Promptarea cu câteva exemple - Învățarea din exemple
- Ghidul de inginerie a prompturilor - Tehnici generale de inginerie a prompturilor
Lectură suplimentară
Referințe
- Zhang et al. (2023) - Multimodal Chain-of-Thought Reasoning in Language Models