
Arborele de gânduri (ToT)
Prezentare generală
Pentru sarcinile complexe care necesită explorare sau privire strategică înainte, tehnicile tradiționale sau simple de promptare nu sunt suficiente. Yao et al. (2023) și Long (2023) au propus recent Arborele de gânduri (ToT), un cadru care generalizează promptarea chain-of-thought și încurajează explorarea gândurilor care servesc ca pași intermediari pentru rezolvarea generală a problemelor cu modelele de limbaj.
Cum funcționează
ToT menține un arbore de gânduri, unde gândurile reprezintă secvențe coerente de limbaj care servesc ca pași intermediari pentru rezolvarea unei probleme. Această abordare permite unui LM să se auto-evalueze progresul prin gândurile intermediare făcute pentru rezolvarea unei probleme printr-un proces deliberat de raționament. Capacitatea LM-ului de a genera și evalua gânduri este apoi combinată cu algoritmi de căutare (de exemplu, căutarea în lățime și căutarea în adâncime) pentru a permite explorarea sistematică a gândurilor cu privire înainte și backtracking.
Cadrul ToT este ilustrat mai jos:
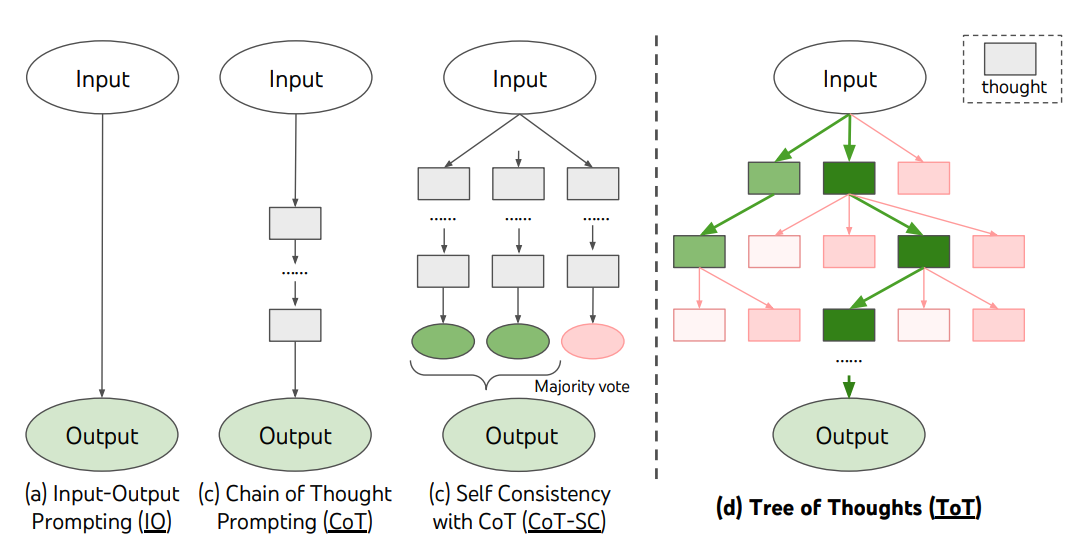
Sursa imaginii: Yao et al. (2023)
Detalii de implementare
Când folosești ToT, sarcinile diferite necesită definirea numărului de candidați și numărul de gânduri/pași. De exemplu, așa cum este demonstrat în lucrare, Jocul de 24 este folosit ca o sarcină de raționament matematic care necesită descompunerea gândurilor în 3 pași, fiecare implicând o ecuație intermediară. La fiecare pas, cei mai buni b=5 candidați sunt păstrați.
Pentru a efectua BFS în ToT pentru sarcina Jocul de 24, LM-ul este promptat să evalueze fiecare candidat de gând ca "sigur/poate/imposibil" în ceea ce privește atingerea lui 24. Așa cum afirmă autorii, "scopul este să promovezi soluțiile parțiale corecte care pot fi verificate în câteva încercări de privire înainte și să elimini soluțiile parțiale imposibile bazate pe bunul simț 'prea mare/mic' și să păstrezi restul 'poate'". Valorile sunt eșantionate de 3 ori pentru fiecare gând. Procesul este ilustrat mai jos:
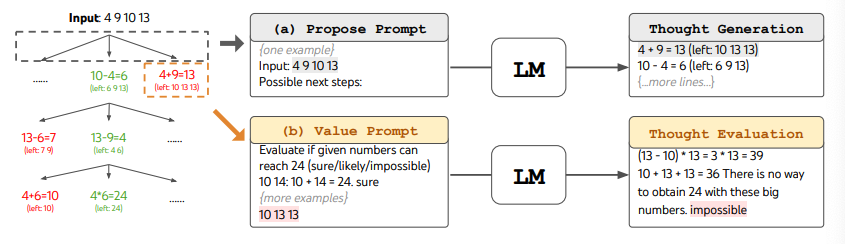
Sursa imaginii: Yao et al. (2023)
Rezultatele de performanță
Din rezultatele raportate în figura de mai jos, ToT depășește substanțial celelalte metode de promptare:
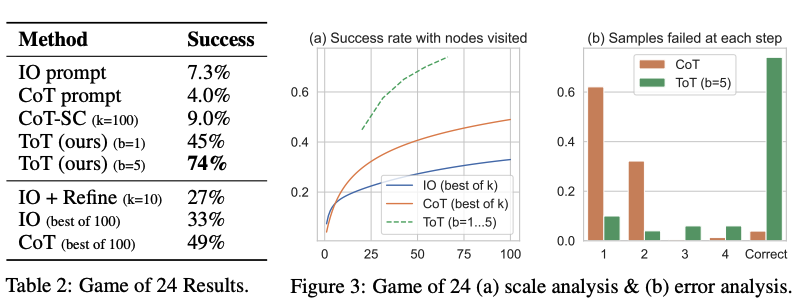
Sursa imaginii: Yao et al. (2023)
Disponibilitatea codului
Comparația cadrelor
La un nivel înalt, ideile principale ale lui Yao et al. (2023) și Long (2023) sunt similare. Ambele îmbunătățesc capacitatea LLM-ului pentru rezolvarea complexă a problemelor prin căutarea în arbore via o conversație în mai multe runde. Una dintre diferențele principale este că Yao et al. (2023) valorifică DFS/BFS/căutarea cu fascicul, în timp ce strategia de căutare în arbore (adică când să faci backtracking și backtracking cu câte niveluri, etc.) propusă în Long (2023) este condusă de un "Controler ToT" antrenat prin învățarea prin întărire. DFS/BFS/Căutarea cu fascicul sunt strategii generice de căutare a soluțiilor fără adaptare la probleme specifice. În comparație, un Controler ToT antrenat prin RL ar putea să învețe din seturi de date noi sau prin auto-joc (AlphaGo vs căutarea cu forța brută), și deci sistemul ToT bazat pe RL poate continua să evolueze și să învețe cunoștințe noi chiar și cu un LLM fix.
Abordări alternative
Hulbert (2023) a propus Promptarea Arborele-de-gânduri, care aplică conceptul principal din cadrele ToT ca o tehnică simplă de promptare, făcând LLM-ul să evalueze gândurile intermediare într-un singur prompt. Un prompt ToT de eșantion este:
Imaginează-ți că trei experți diferiți răspund la această întrebare.
Toți experții vor scrie 1 pas al gândirii lor,
apoi îl vor împărtăși cu grupul.
Apoi toți experții vor continua cu următorul pas, etc.
Dacă orice expert își dă seama că greșește în orice moment, atunci pleacă.
Întrebarea este...Sun (2023) a testat Promptarea Arborele-de-gânduri cu experimente la scară mare și a introdus PanelGPT --- o idee de promptare cu discuții de panel între LLM-uri.
Beneficii cheie
- Explorarea sistematică: Folosește algoritmi de căutare pentru explorarea comprehensivă a problemelor
- Privirea strategică înainte: Evaluează multiple căi înainte de a se angaja la soluții
- Auto-evaluarea: Modelele pot-și evalua propriul progres de raționament
- Căutarea flexibilă: Suportă diverse strategii de căutare (BFS, DFS, căutarea cu fascicul)
- Rezolvarea problemelor complexe: Gestionează sarcinile care necesită raționament în mai mulți pași
Aplicații
- Rezolvarea problemelor matematice: Ecuații complexe și demonstrații
- Jocul: Jocuri strategice care necesită planificare
- Proiectarea algoritmilor: Probleme computaționale în mai mulți pași
- Scrierea creativă: Dezvoltarea narativă structurată
- Planificarea cercetării: Explorarea sistematică a direcțiilor de cercetare
Subiecte conexe
- Promptarea Chain-of-Thought - Înțelegerea tehnicilor de raționament
- Auto-consistența - Multiple căi de raționament
- Ghidul de inginerie a prompturilor - Tehnici generale de inginerie a prompturilor
Referințe
- Yao et al. (2023) - Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Long (2023) - Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Hulbert (2023) - Tree-of-Thought Prompting
- Sun (2023) - PanelGPT: Tree-of-Thought Prompting with Large-Scale Experiments