
Scalarea modelelor de limbaj fine-tunate pentru instrucțiuni
Prezentare generală
Această lucrare explorează beneficiile scalării fine-tuning-ului pentru instrucțiuni și cum îmbunătățește performanța pe o varietate de modele (PaLM, T5), configurații de promptare (zero-shot, few-shot, CoT) și benchmark-uri (MMLU, TyDiQA). Aceasta este explorată cu următoarele aspecte: scalarea numărului de sarcini (1.8K sarcini), scalarea dimensiunii modelului și fine-tuning-ul pe date chain-of-thought (9 seturi de date folosite).
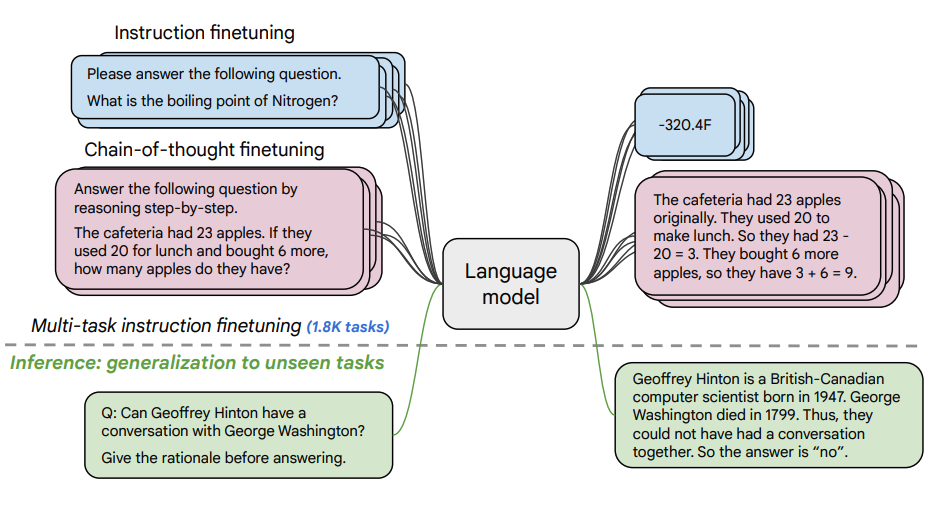
Procedura de fine-tuning
Scalarea sarcinilor
- 1.8K sarcini au fost formulate ca instrucțiuni și folosite pentru fine-tuning-ul modelului
- Folosește atât cu cât și fără exemple, și cu cât și fără CoT
- Sarcinile de fine-tuning și sarcinile reținute sunt arătate mai jos:
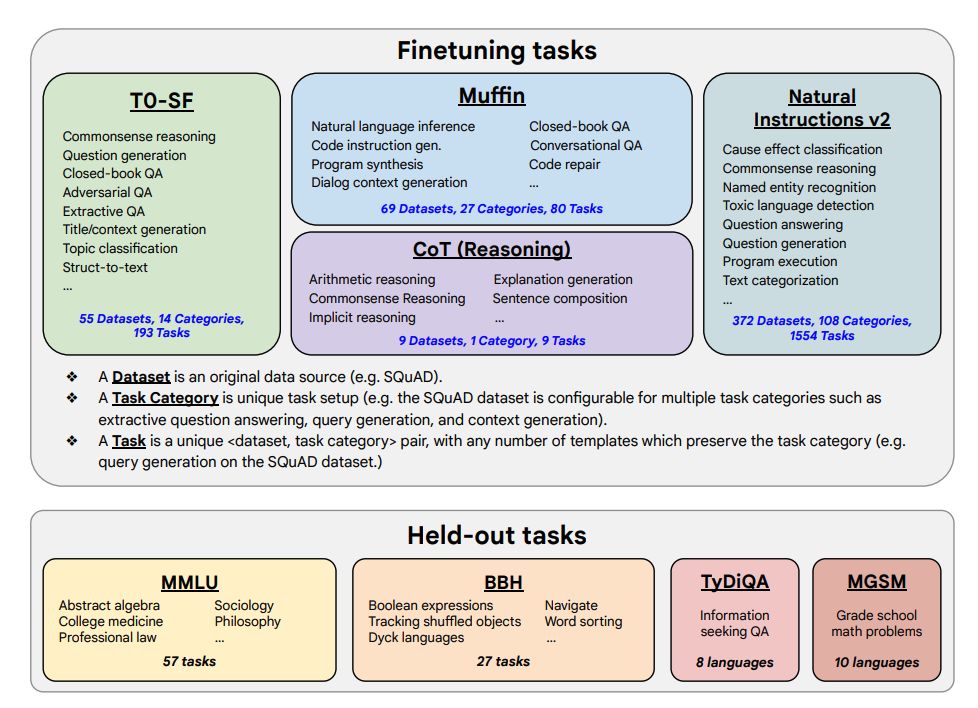
Capacități și rezultate cheie
Îmbunătățirile performanței
- Fine-tuning-ul pentru instrucțiuni scalează bine cu numărul de sarcini și dimensiunea modelului
- Aceasta sugerează necesitatea de a scala mai departe numărul de sarcini și dimensiunea modelului
- Adăugarea seturilor de date CoT în fine-tuning permite performanță bună pe sarcinile de raționament
Capacități multilingve
- Flan-PaLM are abilități multilingve îmbunătățite
- Îmbunătățire de 14.9% pe TyDiQA one-shot
- Îmbunătățire de 8.1% pe raționamentul aritmetic în limbi sub-reprezentate
Calitatea generării
- Plan-PaLM performează bine pe întrebări de generare deschise
- Aceasta este un indicator bun pentru utilizabilitatea îmbunătățită
- Îmbunătățește performanța pe benchmark-urile AI responsabil (RAI)
Compararea modelelor
- Modelele Flan-T5 fine-tunate pentru instrucțiuni demonstrează capacități puternice few-shot
- Depășește checkpoint-urile publice precum T5
Analiza scalării
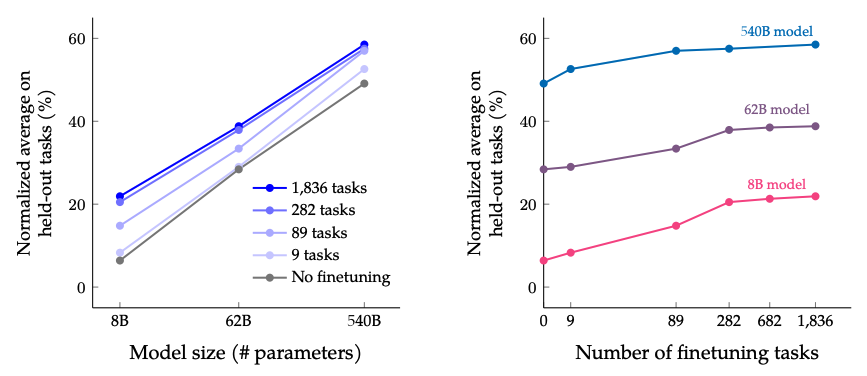
Scalarea sarcinilor și dimensiunii modelului
Rezultatele când se scalează numărul de sarcini de fine-tuning și dimensiunea modelului: scalarea atât a dimensiunii modelului cât și a numărului de sarcini de fine-tuning este așteptată să continue să îmbunătățească performanța, deși scalarea numărului de sarcini are randamente diminuate.
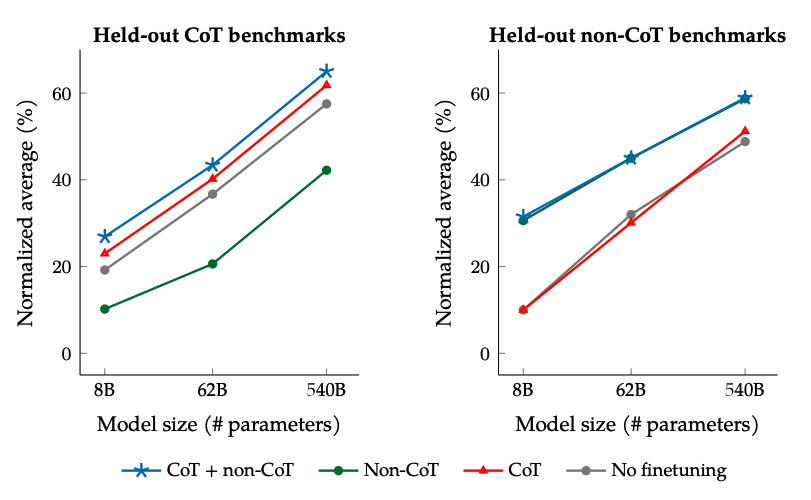
Fine-tuning CoT vs Non-CoT
Rezultatele când se face fine-tuning cu date non-CoT și CoT: Fine-tuning-ul comun pe date non-CoT și CoT îmbunătățește performanța pe ambele evaluări, comparat cu fine-tuning-ul doar pe una sau alta.
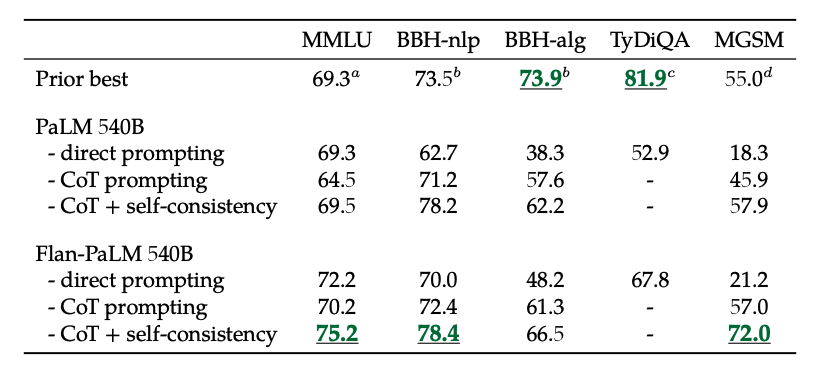
Auto-consistența cu CoT
În plus, auto-consistența combinată cu CoT obține rezultate SoTA pe mai multe benchmark-uri. CoT + auto-consistența îmbunătățește, de asemenea, semnificativ rezultatele pe benchmark-uri care implică probleme de matematică (de ex., MGSM, GSM8K).
Chain-of-Thought Zero-Shot
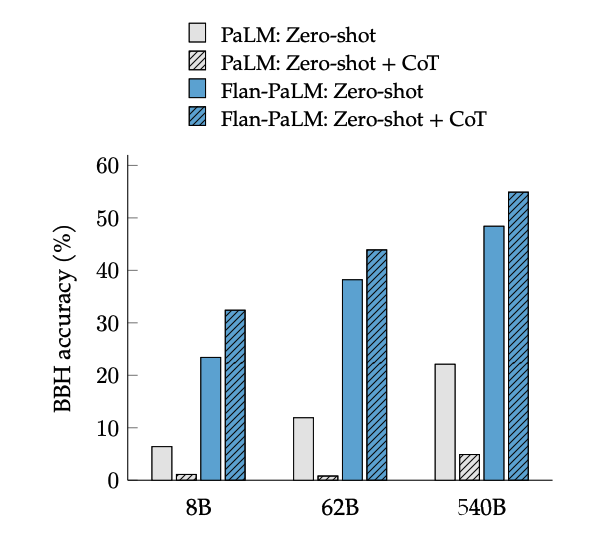
Activarea și performanța
Fine-tuning-ul CoT deblochează raționamentul zero-shot, activat de fraza "să gândim pas cu pas", pe sarcinile BIG-Bench. În general, zero-shot CoT Flan-PaLM depășește zero-shot CoT PaLM fără fine-tuning.
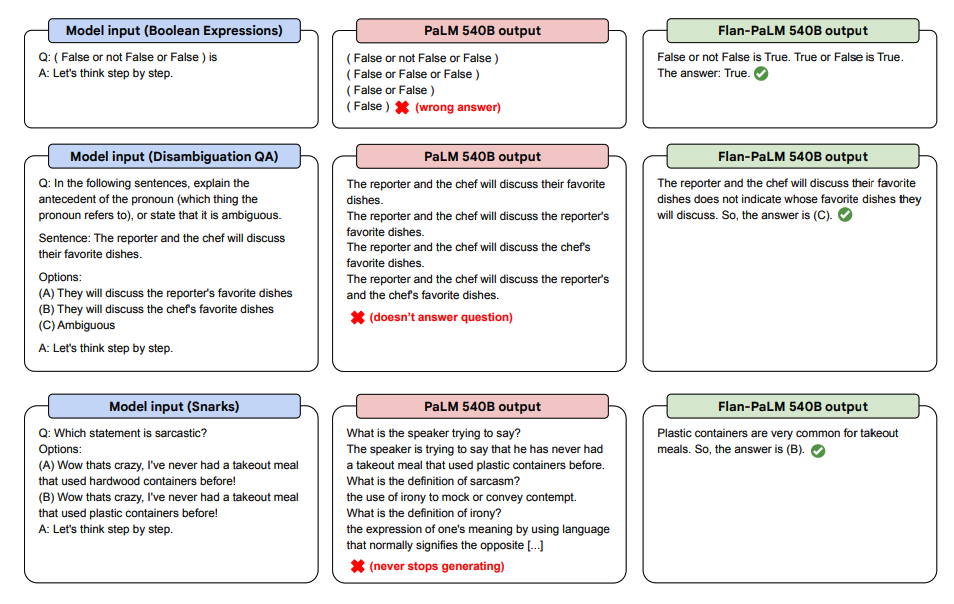
Demonstrațiile zero-shot
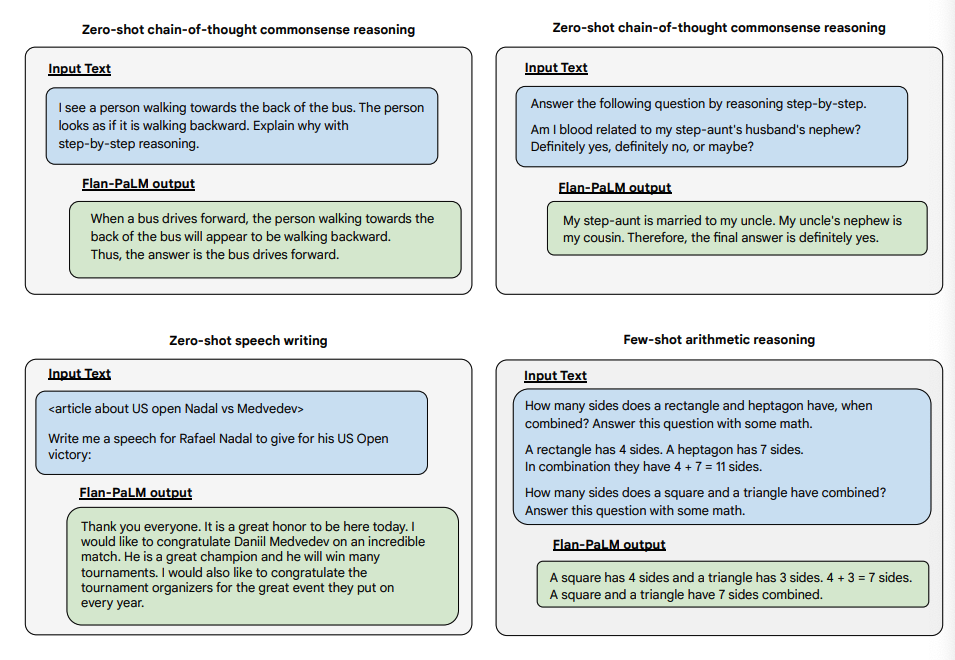
Mai jos sunt câteva demonstrații de zero-shot CoT pentru PaLM și Flan-PaLM în sarcini nevăzute.
Capacități zero-shot suplimentare
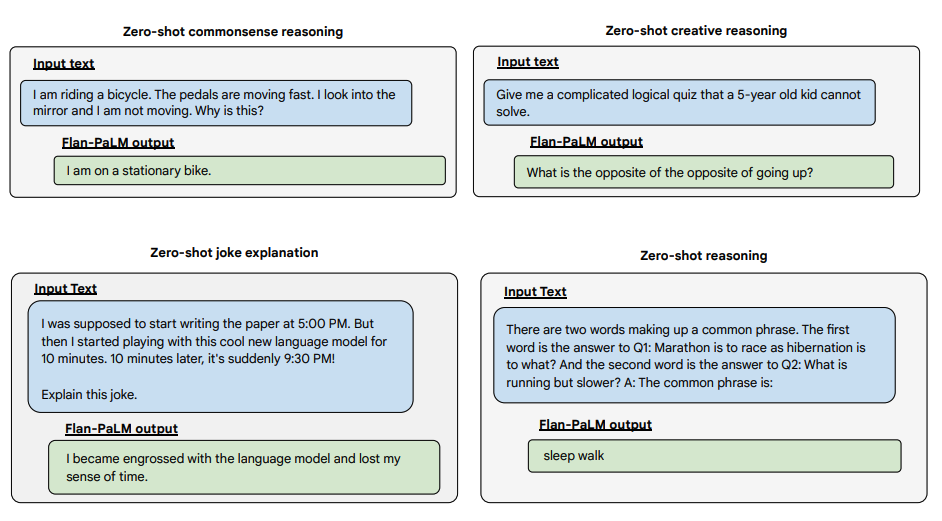
Mai jos sunt mai multe exemple pentru promptarea zero-shot. Arată cum modelul PaLM se luptă cu repetițiile și nu răspunde la instrucțiuni în setarea zero-shot unde Flan-PaLM este capabil să performeze bine. Exemplele few-shot pot atenua aceste erori.

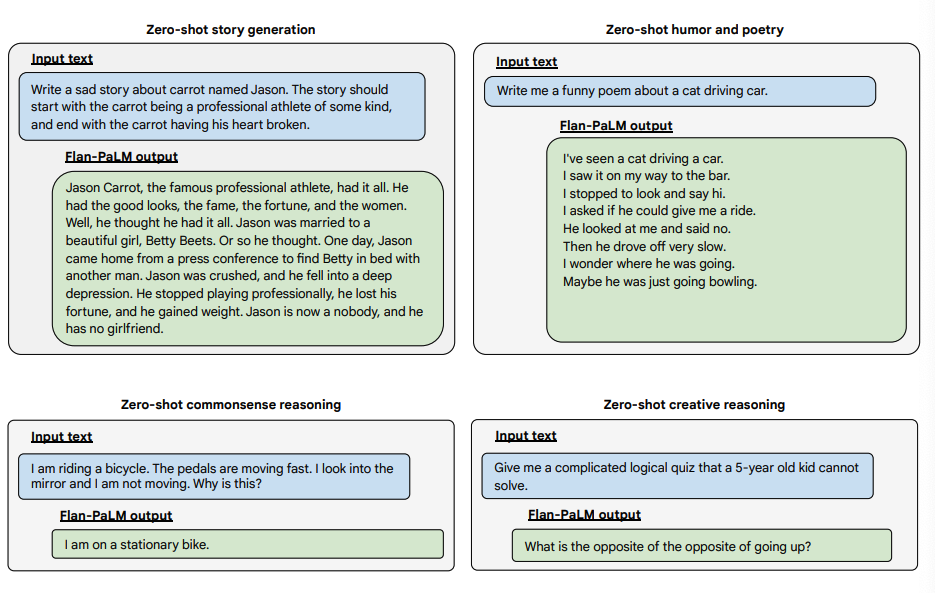
Exemple de întrebări deschise
Mai jos sunt câteva exemple care demonstrează mai multe capacități zero-shot ale modelului Flan-PALM pe mai multe tipuri diferite de întrebări deschise provocatoare:
Încearcă-l
Puteți încerca modelele Flan-T5 pe Hugging Face Hub.
Învățăminte cheie
- Fine-tuning-ul pentru instrucțiuni scalează eficient atât cu numărul de sarcini cât și cu dimensiunea modelului
- Integrarea CoT îmbunătățește semnificativ capacitățile de raționament
- Performanța multilingvă arată îmbunătățiri substanțiale
- Raționamentul zero-shot este deblocat prin fine-tuning-ul corespunzător
- Auto-consistența combinată cu CoT obține rezultate de top
- Generarea deschisă este îmbunătățită semnificativ