
LLaMA: Modele de fundație de limbaj deschise și eficiente
Prezentare generală
Notă: Această secțiune este în curs de dezvoltare intensivă.
Ce este nou?
Această lucrare introduce o colecție de modele de fundație de limbaj care variază de la 7B la 65B de parametri.
Datele de antrenament
Modelele sunt antrenate pe trilioane de tokeni cu seturi de date disponibile public.
Contextul de cercetare
Lucrarea lui (Hoffman et al. 2022) arată că având în vedere un buget de computație, modelele mai mici antrenate pe mult mai multe date pot obține performanță mai bună decât omologii mai mari. Această lucrare recomandă antrenarea modelelor de 10B pe 200B de tokeni.
Descoperirea cheie: Cu toate acestea, lucrarea LLaMA găsește că performanța unui model de 7B continuă să se îmbunătățească chiar și după 1T de tokeni.
Focusul de cercetare
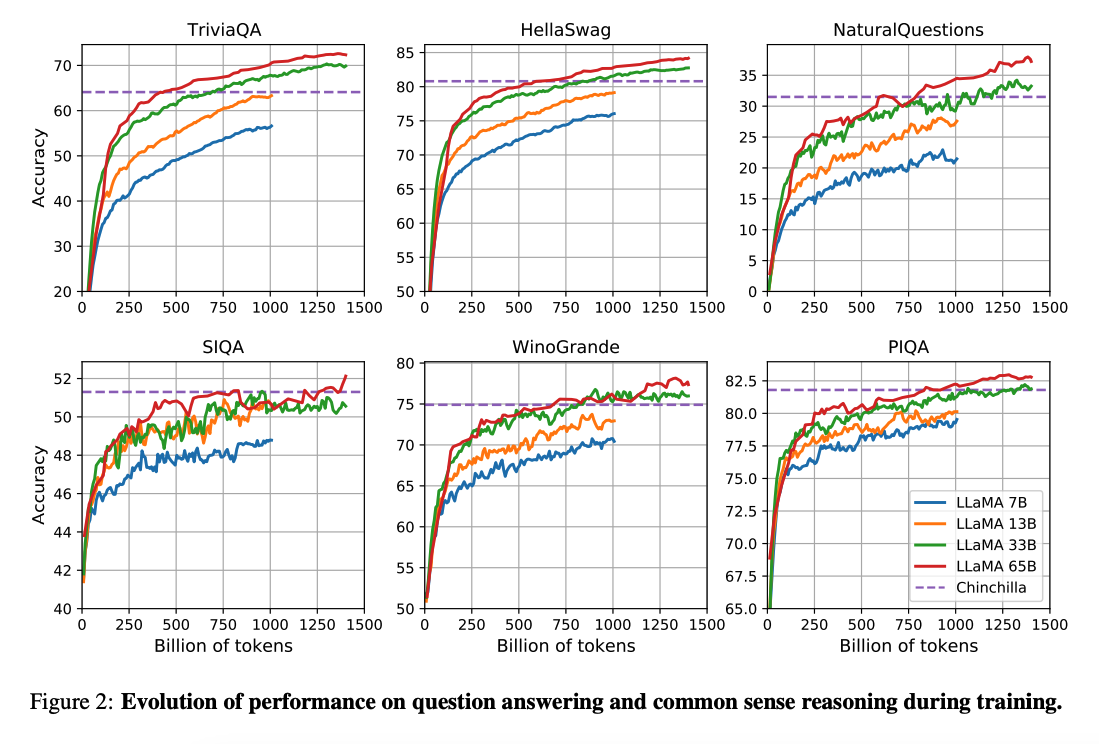
Această lucrare se concentrează pe antrenarea modelelor (LLaMA) care obțin cea mai bună performanță posibilă la diverse bugete de inferență, prin antrenarea pe mai mulți tokeni.
Capacități și rezultate cheie
Compararea performanței
LLaMA-13B depășește GPT-3(175B) pe multe benchmark-uri în ciuda faptului că este:
- De 10 ori mai mic
- Posibil de rulat pe un singur GPU
LLaMA 65B este competitiv cu modele precum:
- Chinchilla-70B
- PaLM-540B
Resurse
Lucrarea
LLaMA: Modele de fundație de limbaj deschise și eficiente
Codul
Referințe
Aprilie 2023
- Koala: Un model de dialog pentru cercetarea academică
- Baize: Un model de chat open-source cu fine-tuning eficient de parametri pe date de auto-chat
Martie 2023
- Vicuna: Un chatbot open-source care impresionează GPT-4 cu 90%* calitate ChatGPT
- LLaMA-Adapter: Fine-tuning eficient al modelelor de limbaj cu atenția zero-init
- GPT4All
- ChatDoctor: Un model de chat medical fine-tunat pe modelul LLaMA folosind cunoștințe de domeniu medical
- Stanford Alpaca
Învățăminte cheie
- Scalarea eficientă: Modelele mai mici antrenate pe mai multe date pot depăși omologii mai mari
- Îmbunătățirea continuă: Performanța modelului de 7B se îmbunătățește chiar și după 1T de tokeni
- Cost-eficient: LLaMA-13B depășește GPT-3(175B) în timp ce este de 10 ori mai mic
- Compatibil cu GPU-ul unic: LLaMA-13B poate rula pe un singur GPU
- Performanță competitivă: LLaMA 65B competă cu modelele de top
- Fundația deschisă: Oferă baza pentru multe modele și aplicații derivate