
Reflexion
Prezentare generală
Reflexion este un cadru pentru a întări agenții bazati pe limbaj prin feedback lingvistic. Conform lui Shinn et al. (2023), "Reflexion este un nou paradigm pentru întărirea 'verbală' care parametrizează o politică ca o codificare a memoriei unui agent împerecheată cu o alegere a parametrilor LLM."
La un nivel înalt, Reflexion convertește feedback-ul (fie limbaj liber sau scalar) din mediu în feedback lingvistic, denumit de asemenea auto-reflexie, care este furnizat ca context pentru un agent LLM în episodul următor. Aceasta ajută agentul să învețe rapid și eficient din greșelile anterioare, conducând la îmbunătățiri ale performanței pe multe sarcini avansate.
Arhitectura cadrului
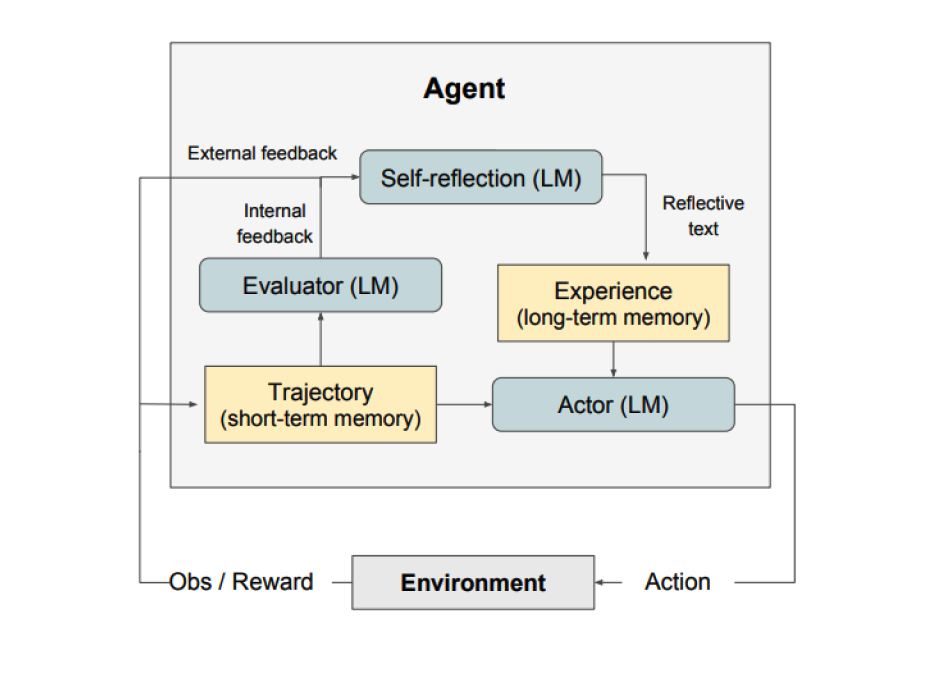
Sursa imaginii: Shinn et al. (2023)
Așa cum se arată în figura de mai sus, Reflexion constă din trei modele distincte:
1. Actorul
Generează text și acțiuni bazate pe observațiile de stare. Actorul ia o acțiune într-un mediu și primește o observație care rezultă într-o traiectorie. Chain-of-Thought (CoT) și ReAct sunt folosite ca modele Actor. O componentă de memorie este de asemenea adăugată pentru a furniza context suplimentar agentului.
2. Evaluatorul
Notează ieșirile produse de Actor. Concret, ia ca intrare o traiectorie generată (denumită de asemenea memorie pe termen scurt) și produce un scor de recompensă. Diferite funcții de recompensă sunt folosite în funcție de sarcină (LLM-urile și euristica bazată pe reguli sunt folosite pentru sarcinile de luare a deciziilor).
3. Auto-reflexia
Generează indicii verbale de întărire pentru a asista Actorul în auto-îmbunătățire. Acest rol este realizat de un LLM și furnizează feedback valoros pentru încercările viitoare. Pentru a genera feedback specific și relevant, care este de asemenea stocat în memorie, modelul de auto-reflexie folosește semnalul de recompensă, traiectoria curentă și memoria sa persistentă. Aceste experiențe (stocate în memoria pe termen lung) sunt valorificate de agent pentru a îmbunătăți rapid luarea deciziilor.
Cum funcționează
În rezumat, pașii cheie ai procesului Reflexion sunt:
- Definește o sarcină
- Generează o traiectorie
- Evaluează
- Efectuează reflexia
- Generează următoarea traiectorie
Figura de mai jos demonstrează exemple de cum un agent Reflexion poate învăța să-și optimizeze iterativ comportamentul pentru a rezolva diverse sarcini precum luarea deciziilor, programarea și raționamentul. Reflexion extinde cadrul ReAct prin introducerea auto-evaluării, auto-reflexiei și componentelor de memorie.
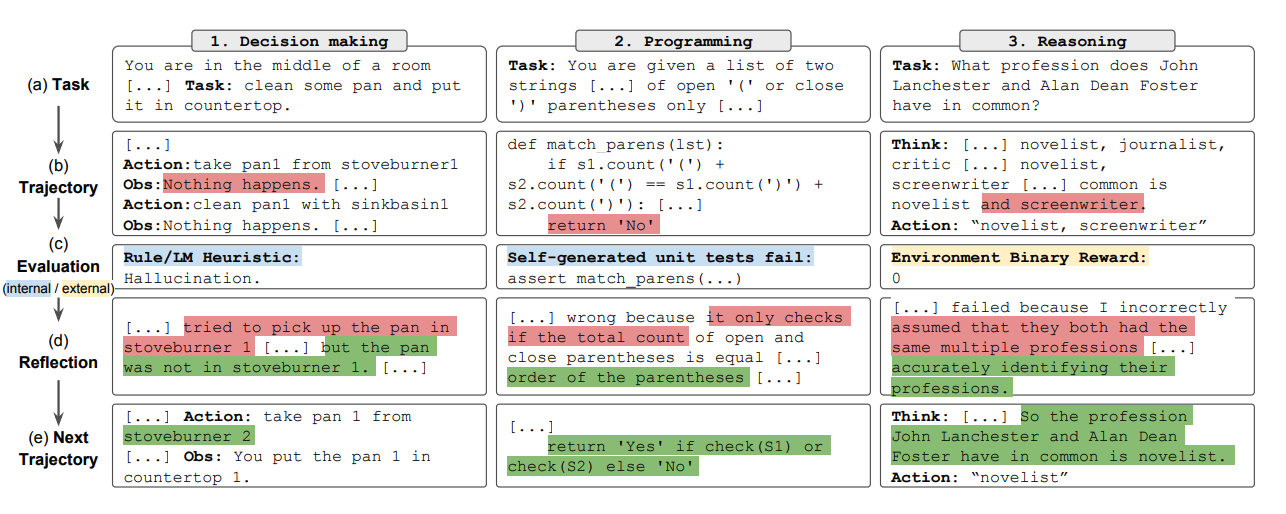
Sursa imaginii: Shinn et al. (2023)
Rezultatele de performanță
Sarcini de luare a deciziilor secvențiale
Rezultatele experimentale demonstrează că agenții Reflexion îmbunătățesc semnificativ performanța pe sarcinile de luare a deciziilor AlfWorld, întrebările de raționament din HotPotQA și sarcinile de programare Python pe HumanEval.
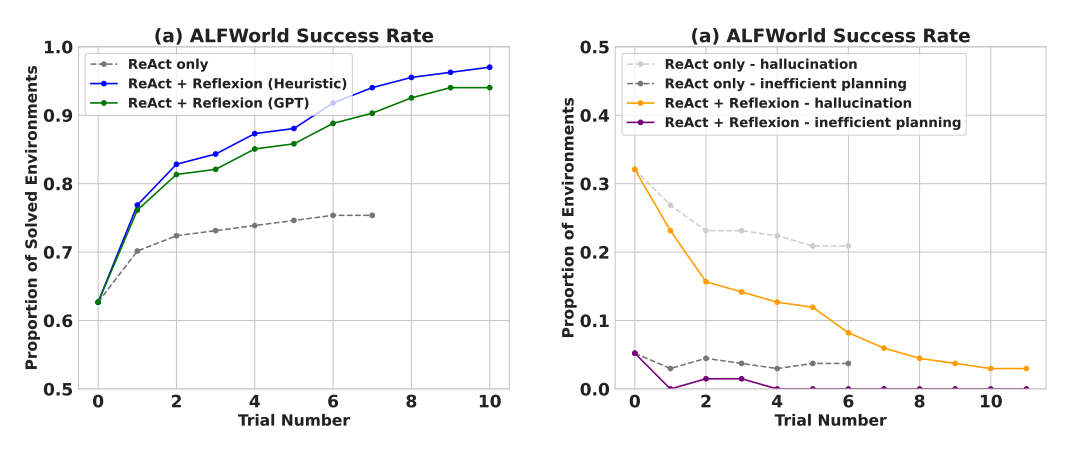
Când este evaluat pe sarcinile de luare a deciziilor secvențiale (AlfWorld), ReAct + Reflexion depășește semnificativ ReAct prin completarea a 130/134 sarcini folosind tehnici de auto-evaluare de Heuristic și GPT pentru clasificarea binară.
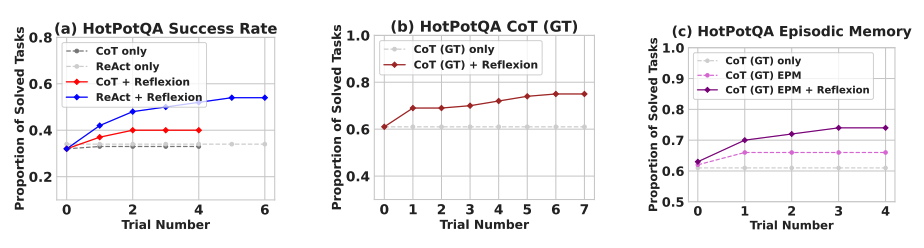
Sursa imaginii: Shinn et al. (2023)
Reflexion depășește semnificativ toate abordările de bază pe mai mulți pași de învățare. Pentru raționament doar și când se adaugă o memorie episodică constând din traiectoria cea mai recentă, Reflexion + CoT depășește CoT doar și CoT cu memorie episodică, respectiv.
Sarcinile de programare
Așa cum este rezumat în tabelul de mai jos, Reflexion depășește în general abordările anterioare de ultimă generație pe scrierea de cod Python și Rust pe MBPP, HumanEval și Leetcode Hard.

Sursa imaginii: Shinn et al. (2023)
Când să folosești Reflexion
Reflexion este cel mai potrivit pentru următoarele scenarii:
1. Învățarea din încercări și erori
Un agent trebuie să învețe din încercări și erori: Reflexion este proiectat să ajute agenții să-și îmbunătățească performanța prin reflectarea asupra greșelilor anterioare și încorporarea acelor cunoștințe în deciziile viitoare. Aceasta îl face potrivit pentru sarcinile unde agentul trebuie să învețe prin încercări și erori, precum luarea deciziilor, raționamentul și programarea.
2. Alternativă la RL tradițional
Metodele tradiționale de învățare prin întărire (RL) sunt nepractice: Metodele tradiționale de învățare prin întărire (RL) adesea necesită date extensive de antrenament și finetuning scump al modelului. Reflexion oferă o alternativă ușoară care nu necesită finetuning-ul modelului de limbaj de bază, făcându-l mai eficient în ceea ce privește datele și resursele computaționale.
3. Cerințele de feedback nuanțat
Feedback-ul nuanțat este necesar: Reflexion utilizează feedback verbal, care poate fi mai nuanțat și specific decât recompensele scalare folosite în RL tradițional. Aceasta permite agentului să înțeleagă mai bine greșelile sale și să facă îmbunătățiri mai țintite în încercările ulterioare.
4. Interpretabilitatea și memoria
Interpretabilitatea și memoria explicită sunt importante: Reflexion furnizează o formă mai interpretabilă și explicită de memorie episodică comparativ cu metodele tradiționale RL. Auto-reflexiile agentului sunt stocate în memoria sa, permițând o analiză și înțelegere mai ușoară a procesului său de învățare.
Aplicații eficiente
Reflexion este eficient în următoarele sarcini:
- Luarea deciziilor secvențiale: Agenții Reflexion își îmbunătățesc performanța în sarcinile AlfWorld, care implică navigarea prin diverse medii și completarea obiectivelor în mai mulți pași.
- Raționamentul: Reflexion a îmbunătățit performanța agenților pe HotPotQA, un set de date de răspunsuri la întrebări care necesită raționament pe mai multe documente.
- Programarea: Agenții Reflexion scriu cod mai bun pe benchmark-uri precum HumanEval și MBPP, atingând rezultate de ultimă generație în unele cazuri.
Limitări
Iată unele limitări ale Reflexion:
1. Dependențele de auto-evaluare
Dependența de capacitățile de auto-evaluare: Reflexion se bazează pe capacitatea agentului de a-și evalua cu acuratețe performanța și de a genera auto-reflexii utile. Aceasta poate fi provocator, mai ales pentru sarcini complexe, dar se așteaptă ca Reflexion să devină mai bun în timp pe măsură ce modelele își îmbunătățesc continuu capacitățile.
2. Constrângerile memoriei
Constrângerile memoriei pe termen lung: Reflexion folosește o fereastră glisantă cu capacitate maximă, dar pentru sarcini mai complexe ar putea fi avantajos să folosești structuri avansate precum încorporări vectoriale sau baze de date SQL.
3. Limitările generării de cod
Limitările generării de cod: Există limitări la dezvoltarea condusă de teste în specificarea mapărilor precise de intrare-ieșire (de exemplu, funcția generator non-deterministă și ieșirile funcției influențate de hardware).
Beneficii cheie
- Auto-îmbunătățirea: Agenții învață din propriile greșeli și experiențe
- Feedback-ul lingvistic: Mai nuanțat decât recompensele scalare tradiționale
- Integrarea memoriei: Învățarea persistentă pe mai multe episoade
- Nu necesită finetuning: Funcționează cu modele de limbaj înghețate
- Învățarea interpretabilă: Înțelegerea clară a ceea ce învață agentul
Aplicații
- Jocul: Învățarea strategiilor optimale prin auto-reflexie
- Generarea de cod: Îmbunătățirea abilităților de programare iterativ
- Sarcinile de raționament: Îmbunătățirea capacităților de gândire logică
- Luarea deciziilor: Învățarea unor politici mai bune prin experiență
Subiecte conexe
- Promptarea Chain-of-Thought - Înțelegerea tehnicilor de raționament
- Promptarea ReAct - Combinarea raționamentului și acționării
- Ghidul de inginerie a prompturilor - Tehnici generale de inginerie a prompturilor
Referințe
- Reflexion: Language Agents with Verbal Reinforcement Learning
- Can LLMs Critique and Iterate on Their Own Outputs?
Sursa figurilor: Reflexion: Language Agents with Verbal Reinforcement Learning