
Subiecte diverse
În această secțiune, discutăm alte subiecte diverse și necategorizate în ingineria prompturilor. Include idei și abordări relativ noi care vor fi eventual mutate în ghidurile principale pe măsură ce devin mai acceptate pe scară largă. Această secțiune a ghidului este de asemenea utilă pentru a ține pasul cu cele mai recente lucrări de cercetare despre ingineria prompturilor.
Reține că această secțiune este în curs de dezvoltare intensă.
Subiecte:
Active-Prompt
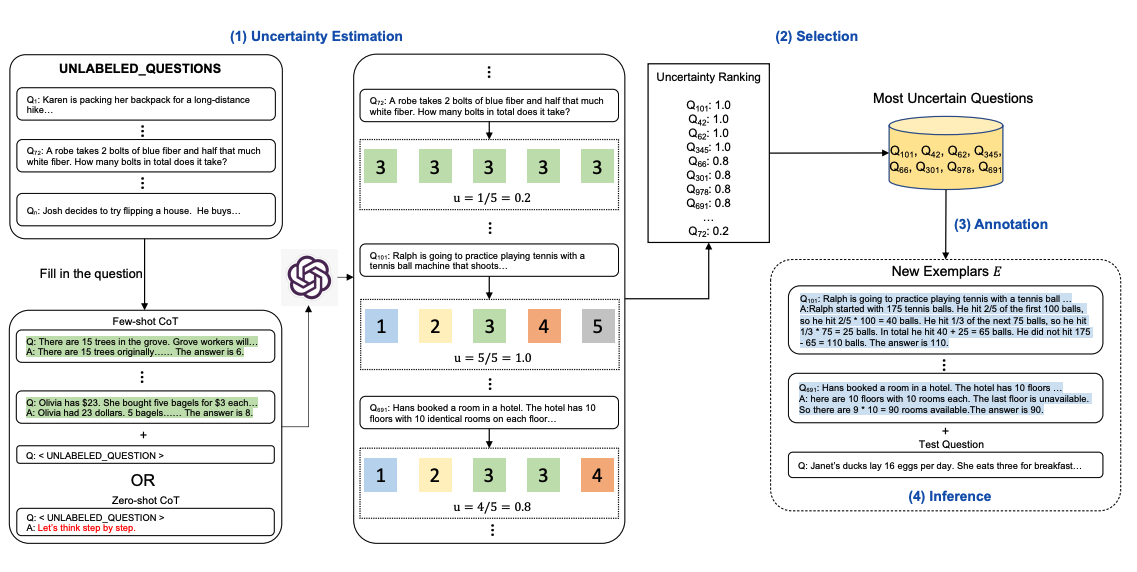
Metodele chain-of-thought (CoT) se bazează pe un set fix de exemple anotate de oameni. Problema cu aceasta este că exemplele s-ar putea să nu fie cele mai eficiente exemple pentru sarcinile diferite. Pentru a aborda aceasta, Diao et al., (2023) au propus recent o nouă abordare de promptare numită Active-Prompt pentru a adapta LLM-urile la diferite prompturi de exemple specifice sarcinilor (anotate cu raționament CoT proiectat de oameni).
Mai jos este o ilustrare a abordării. Primul pas este să interoghezi LLM-ul cu sau fără câteva exemple CoT. k răspunsuri posibile sunt generate pentru un set de întrebări de antrenament. O metrică de incertitudine este calculată pe baza celor k răspunsuri (se folosește dezacordul). Cele mai nesigure întrebări sunt selectate pentru anotarea de către oameni. Noile exemple anotate sunt apoi folosite pentru a infera fiecare întrebare.
Promptarea cu stimul direcțional
Li et al., (2023) propune o nouă tehnică de promptare pentru a ghida mai bine LLM-ul în generarea rezumatului dorit.
Un LM de politică ajustabil este antrenat pentru a genera stimulul/indiciul. Se vede mai multă folosire a RL pentru a optimiza LLM-urile.
Figura de mai jos arată cum se compară Promptarea cu stimul direcțional cu promptarea standard. LM-ul de politică poate fi mic și optimizat pentru a genera indiciile care ghidează un LLM înghețat black-box.

Exemplul complet vine în curând!
ReAct
Yao et al., 2022 au introdus un cadru unde LLM-urile sunt folosite pentru a genera atât urme de raționament cât și acțiuni specifice sarcinilor într-un mod intercalat. Generarea urmelor de raționament permite modelului să inducă, să urmărească și să actualizeze planuri de acțiune, și chiar să gestioneze excepții. Pasul de acțiune permite să se interfațeze cu și să colecteze informații din surse externe precum bazele de cunoștințe sau medii.
Cadrul ReAct poate permite LLM-urilor să interacționeze cu instrumente externe pentru a prelua informații suplimentare care duc la răspunsuri mai fiabile și factuale.

Exemplul complet vine în curând!
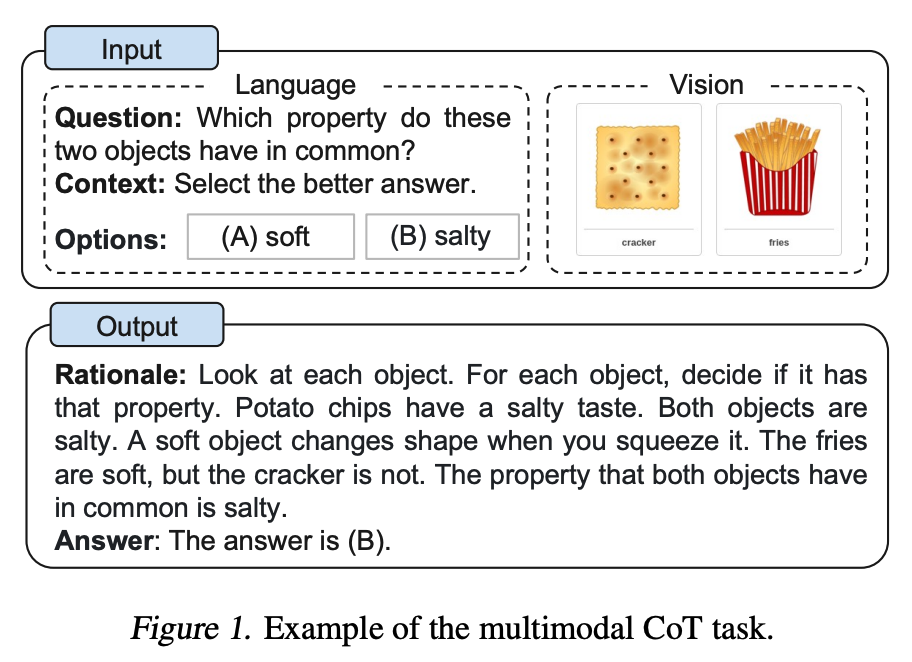
Promptarea multimodală CoT
Zhang et al. (2023) au propus recent o abordare de promptare multimodală chain-of-thought. CoT-ul tradițional se concentrează pe modalitatea de limbaj. În contrast, CoT-ul multimodal încorporează text și viziune într-un cadru în două etape. Primul pas implică generarea raționamentului pe baza informațiilor multimodale. Aceasta este urmată de a doua fază, inferența răspunsului, care valorifică raționamentele informative generate.
Modelul multimodal CoT (1B) depășește GPT-3.5 pe benchmark-ul ScienceQA.
Lectură suplimentară:
GraphPrompts
Liu et al., 2023 introduce GraphPrompt, un nou cadru de promptare pentru grafuri pentru a îmbunătăți performanța pe sarcinile downstream.
Mai multe vin în curând!