
Promptarea ReAct
Prezentare generală
Yao et al., 2022 au introdus un cadru numit ReAct unde LLM-urile sunt folosite pentru a genera atât urme de raționament cât și acțiuni specifice sarcinilor într-un mod intercalat.
Generarea urmelor de raționament permite modelului să inducă, să urmărească și să actualizeze planuri de acțiune, și chiar să gestioneze excepții. Pasul de acțiune permite interfațarea cu și colectarea de informații din surse externe precum bazele de cunoștințe sau medii.
Beneficii cheie
Cadrul ReAct poate permite LLM-urilor să interacționeze cu instrumente externe pentru a recupera informații suplimentare care conduc la răspunsuri mai de încredere și factuale.
Rezultatele arată că ReAct poate depăși mai multe linii de bază de ultimă generație la sarcinile de limbaj și luarea deciziilor. ReAct conduce de asemenea la îmbunătățirea interpretabilității umane și încrederii în LLM-uri. În general, autorii au descoperit că cea mai bună abordare folosește ReAct combinat cu chain-of-thought (CoT) care permite utilizarea atât a cunoștințelor interne cât și a informațiilor externe obținute în timpul raționamentului.
Cum funcționează
ReAct este inspirat de sinergiile între "acționarea" și "raționamentul" care permit oamenilor să învețe sarcini noi și să ia decizii sau să raționeze.
Promptarea chain-of-thought (CoT) a arătat capacitățile LLM-urilor de a efectua urme de raționament pentru a genera răspunsuri la întrebări care implică raționament aritmetic și de bun simț, printre alte sarcini (Wei et al., 2022). Dar lipsa sa de acces la lumea externă sau incapacitatea de a-și actualiza cunoștințele poate duce la probleme precum halucinația faptelor și propagarea erorilor.
ReAct este un paradigm general care combină raționamentul și acționarea cu LLM-uri. ReAct promptează LLM-urile să genereze urme verbale de raționament și acțiuni pentru o sarcină. Aceasta permite sistemului să efectueze raționament dinamic pentru a crea, menține și ajusta planuri pentru acționare în timp ce permite și interacțiunea cu medii externe (de exemplu, Wikipedia) pentru a încorpora informații suplimentare în raționament. Figura de mai jos arată un exemplu de ReAct și pașii diferiți implicați pentru a efectua răspunsurile la întrebări.

Sursa imaginii: Yao et al. (2022)
Exemplu de implementare
În exemplul de mai sus, transmitem un prompt precum următoarea întrebare din HotpotQA:
În afară de Apple Remote, ce alte dispozitive pot controla programul cu care Apple Remote a fost proiectat inițial să interacționeze?Observă că exemplele în context sunt de asemenea adăugate la prompt, dar le excludem aici pentru simplitate. Putem vedea că modelul generează traiectorii de rezolvare a sarcinilor (Gând, Acțiune). Obs corespunde observației din mediul cu care se interacționează (de exemplu, motorul de căutare). În esență, ReAct poate recupera informații pentru a susține raționamentul, în timp ce raționamentul ajută la țintirea a ceea ce să recupereze în continuare.
Promptarea ReAct în practică
Pentru a demonstra cum funcționează promptarea ReAct, să urmărim un exemplu din lucrare.
Primul pas este să selectezi cazuri dintr-un set de antrenament (de exemplu, HotPotQA) și să compui traiectorii în format ReAct. Acestea sunt folosite ca exemplare cu câteva exemple în prompturi. Traiectoriile constau din multiple pași gând-acțiune-observație așa cum se arată în figura de mai sus. Gândurile libere sunt folosite pentru a realiza sarcini diferite precum descompunerea întrebărilor, extragerea informațiilor, efectuarea raționamentului de bun simț/aritmetic, ghidarea formulării căutării și sinteza răspunsului final.
Exemplu de prompt ReAct
Iată un exemplu de cum arată exemplarele de prompt ReAct (obținute din lucrare și scurtate la un exemplu pentru simplitate):
Întrebare Care este intervalul de elevație pentru zona în care se extinde sectorul estic al
orogenezei Colorado?
Gând 1 Trebuie să caut orogeneza Colorado, să găsesc zona în care se extinde sectorul estic
al orogenezei Colorado, apoi să găsesc intervalul de elevație al
zonei.
Acțiune 1 Căutare[orogeneza Colorado]
Observația 1 Orogeneza Colorado a fost un episod de construire a munților (o orogeneză) în
Colorado și zonele înconjurătoare.
Gând 2 Nu menționează sectorul estic. Deci trebuie să caut sectorul estic.
Acțiune 2 Căutare[sectorul estic]
Observația 2 (Rezultat 1 / 1) Sectorul estic se extinde în Înălțimile și se numește
orogeneza Înălțimilor Centrale.
Gând 3 Sectorul estic al orogenezei Colorado se extinde în Înălțimile. Deci trebuie să
caut Înălțimile și să găsesc intervalul lor de elevație.
Acțiune 3 Căutare[Înălțimile]
Observația 3 Înălțimile se referă la una dintre cele două regiuni de teren distincte
Gând 4 Trebuie să caut în schimb Înălțimile (Statele Unite).
Acțiune 4 Căutare[Înălțimile (Statele Unite)]
Observația 4 Înălțimile sunt o subregiune a Înălțimilor Mari. De la est la vest,
Înălțimile cresc în elevație de la aproximativ 1.800 la 7.000 ft (550 la 2.130
m).[3]
Gând 5 Înălțimile cresc în elevație de la aproximativ 1.800 la 7.000 ft, deci răspunsul
este 1.800 la 7.000 ft.
Acțiune 5 Finalizare[1.800 la 7.000 ft]
...Observă că diferite configurații de prompturi sunt folosite pentru diferite tipuri de sarcini. Pentru sarcinile unde raționamentul este de importanță primară (de exemplu, HotpotQA), multiple pași gând-acțiune-observație sunt folosiți pentru traiectoria de rezolvare a sarcinii. Pentru sarcinile de luare a deciziilor care implică mulți pași de acțiune, gândurile sunt folosite rar.
Rezultatele de performanță
Sarcini intensive în cunoștințe
Lucrarea evaluează mai întâi ReAct pe sarcini intensive în cunoștințe de raționament precum răspunsurile la întrebări (HotPotQA) și verificarea faptelor (Fever). PaLM-540B este folosit ca model de bază pentru promptare.
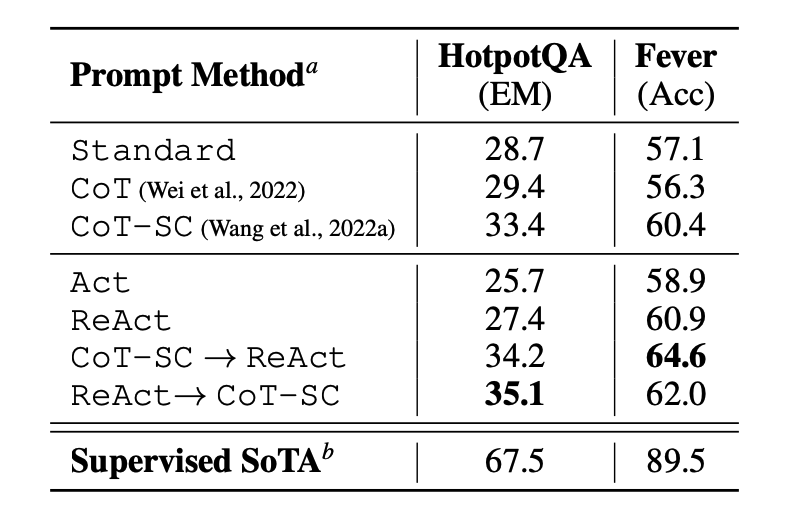
Sursa imaginii: Yao et al. (2022)
Rezultatele de promptare pe HotPotQA și Fever folosind diferite metode de promptare arată că ReAct performează în general mai bine decât Act (implică doar acționarea) pe ambele sarcini.
Putem observa de asemenea că ReAct depășește CoT pe Fever și rămâne în urma CoT pe HotpotQA. O analiză detaliată a erorilor este furnizată în lucrare. În rezumat:
- CoT suferă de halucinația faptelor
- Constrângerea structurală a ReAct îi reduce flexibilitatea în formularea pașilor de raționament
- ReAct depinde mult de informațiile pe care le recuperează; rezultatele de căutare neinformative deraiază raționamentul modelului și duce la dificultăți în recuperarea și reformularea gândurilor
Metodele de promptare care combină și suportă comutarea între ReAct și CoT+Auto-consistență depășesc în general toate celelalte metode de promptare.
Sarcini de luare a deciziilor
Lucrarea raportează de asemenea rezultate demonstrând performanța ReAct pe sarcinile de luare a deciziilor. ReAct este evaluat pe două benchmark-uri numite ALFWorld (joc bazat pe text) și WebShop (mediu de site web de cumpărături online). Ambele implică medii complexe care necesită raționament pentru a acționa și explora eficient.
Observă că prompturile ReAct sunt proiectate diferit pentru aceste sarcini, menținând în continuare aceeași idee de bază de combinare a raționamentului și acționării. Mai jos este un exemplu pentru o problemă ALFWorld care implică promptarea ReAct.
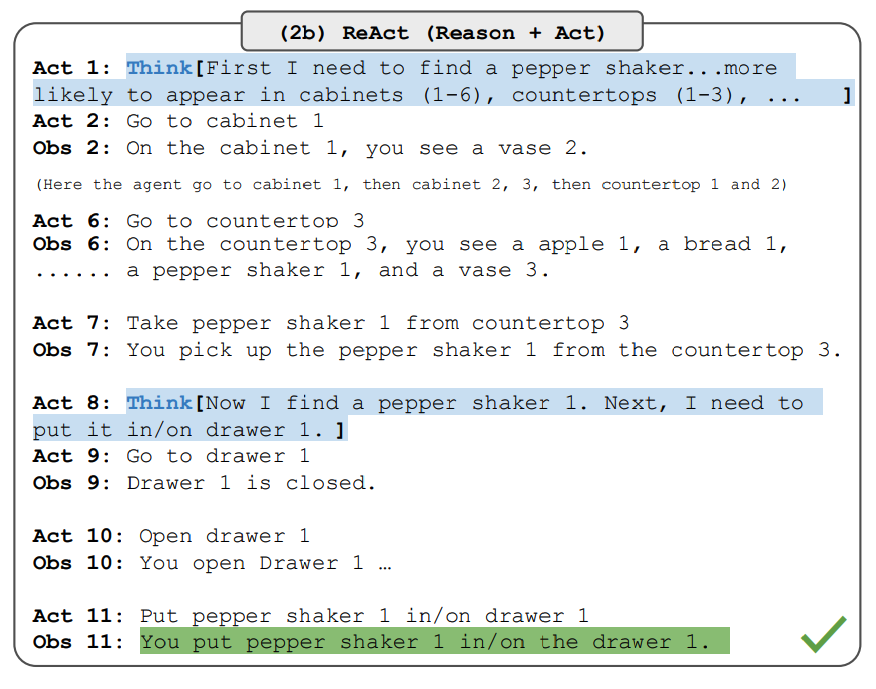
Sursa imaginii: Yao et al. (2022)
ReAct depășește Act pe ambele ALFWorld și Webshop. Act, fără niciun gând, eșuează să descompună corect obiectivele în subobiective. Raționamentul pare să fie avantajos în ReAct pentru aceste tipuri de sarcini, dar metodele actuale bazate pe promptare sunt încă departe de performanța oamenilor experți pe aceste sarcini.
Verifică lucrarea pentru rezultate mai detaliate.
Utilizarea ReAct în LangChain
Mai jos este un exemplu de nivel înalt despre cum funcționează abordarea de promptare ReAct în practică. Vom folosi OpenAI pentru LLM și LangChain deoarece are deja funcționalitatea integrată care valorifică cadrul ReAct pentru a construi agenți care efectuează sarcini prin combinarea puterii LLM-urilor și a diferitelor instrumente.
Instalarea și configurarea
Mai întâi, să instalăm și să importăm bibliotecile necesare:
%%capture
# actualizează sau instalează bibliotecile necesare
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# importă bibliotecile
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# încarcă cheile API; va trebui să le obții dacă nu le ai încă
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")Configurarea agentului
Acum putem configura LLM-ul, instrumentele pe care le vom folosi și agentul care ne permite să valorificăm cadrul ReAct împreună cu LLM-ul și instrumentele. Observă că folosim un API de căutare pentru căutarea informațiilor externe și LLM ca instrument matematic.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)Rularea agentului
Odată ce este configurat, putem acum rula agentul cu interogarea/promptul dorit. Observă că aici nu ne așteptăm să furnizăm exemplare cu câteva exemple așa cum este explicat în lucrare.
agent.run("Cine este iubitul Oliviei Wilde? Care este vârsta sa actuală ridicată la puterea 0.23?")Execuția lanțului arată după cum urmează:
> Intrând în noul lanț AgentExecutor...
Trebuie să aflu cine este iubitul Oliviei Wilde și apoi să calculez vârsta sa ridicată la puterea 0.23.
Acțiune: Căutare
Intrarea acțiunii: "Olivia Wilde iubit"
Observația: Olivia Wilde a început să se întâlnească cu Harry Styles după ce și-a încheiat logodna de ani cu Jason Sudeikis — vezi cronologia relației lor.
Gând: Trebuie să aflu vârsta lui Harry Styles.
Acțiune: Căutare
Intrarea acțiunii: "Harry Styles vârstă"
Observația: 29 de ani
Gând: Trebuie să calculez 29 ridicat la puterea 0.23.
Acțiune: Calculator
Intrarea acțiunii: 29^0.23
Observația: Răspuns: 2.169459462491557
Gând: Acum știu răspunsul final.
Răspunsul final: Harry Styles, iubitul Oliviei Wilde, are 29 de ani și vârsta sa ridicată la puterea 0.23 este 2.169459462491557.
> Lanțul terminat.Ieșirea pe care o obținem este următoarea:
"Harry Styles, iubitul Oliviei Wilde, are 29 de ani și vârsta sa ridicată la puterea 0.23 este 2.169459462491557."Am adaptat exemplul din documentația LangChain, deci creditul le aparține lor. Încurajăm învățătorul să exploreze diferite combinații de instrumente și sarcini.
Beneficii cheie
- Combină raționamentul și acționarea: Integrează gândirea logică cu folosirea instrumentelor externe
- Accesul la informații externe: Recuperează informații în timp real din surse externe
- Acuratețea factuală îmbunătățită: Reduce halucinația prin verificarea externă
- Interpretabilitatea umană: Urme clare de raționament pentru o înțelegere mai bună
- Integrarea flexibilă a instrumentelor: Funcționează cu diverse instrumente externe și API-uri
Aplicații
- Răspunsurile la întrebări: Întrebări complexe care necesită informații externe
- Luarea deciziilor: Sarcini care implică explorarea și planificarea
- Sarcinile de cercetare: Colectarea și sinteza informațiilor
- IA augmentată cu instrumente: Sisteme care combină LLM-urile cu capacități externe
Subiecte conexe
- Promptarea Chain-of-Thought - Înțelegerea tehnicilor de raționament
- Raționamentul automat și folosirea instrumentelor - Abordări de integrare a instrumentelor
- Ghidul de inginerie a prompturilor - Tehnici generale de inginerie a prompturilor
Referințe
- Yao et al., (2022) - ReAct: Synergizing Reasoning and Acting in Language Models
- Documentația LangChain - Exemple de agenți ReAct
Resurse suplimentare
Poți găsi notebook-ul pentru acest cod aici: Notebook ReAct