
Gemini 1.5 Pro
Prezentare generală
Google introduce Gemini 1.5 Pro, un model AI multimodal eficient computațional de tip mixture-of-experts. Acest model AI se concentrează pe capacități precum reamintirea și raționarea asupra conținutului de formă lungă. Gemini 1.5 Pro poate raționa asupra documentelor lungi care pot conține potențial milioane de tokeni, inclusiv ore de video și audio.
Capacități cheie
- Procesarea conținutului de formă lungă: Milioane de tokeni, ore de video și audio
- Performanță de top în QA pe documente lungi, QA pe video lung și ASR cu context lung
- Se potrivește sau depășește Gemini 1.0 Ultra pe benchmark-urile standard
- Recuperare aproape perfectă (>99%) până la cel puțin 10 milioane de tokeni
- Fereastra de context de 1 milion de tokeni disponibilă în Google AI Studio
Compararea ferestrei de context
- 200K tokeni: Cea mai mare fereastră de context a oricărui LLM disponibil până în prezent
- 1 milion de tokeni: Noua capacitate experimentală în Google AI Studio
- 10 milioane de tokeni: Capacitatea maximă demonstrată
Arhitectura
Gemini 1.5 Pro este un model Transformer sparse mixture-of-experts (MoE) bazat pe capacitățile multimodale Gemini 1.0.
Caracteristici cheie
- Arhitectura MoE: Parametrii totali pot crește păstrând parametrii activați constanți
- Antrenament eficient: Semnificativ mai puțină computație de antrenament necesară
- Servire eficientă: Mai eficient de servit decât modelele anterioare
- Înțelegerea contextului lung: Schimbările de arhitectură permit procesarea până la 10 milioane de tokeni
- Pre-antrenament multimodal: Antrenat pe diferite modalități cu fine-tuning pentru instrucțiuni
- Fine-tuning pentru preferințele umane: Îmbunătățit în continuare pe baza datelor de preferințe umane
Rezultate
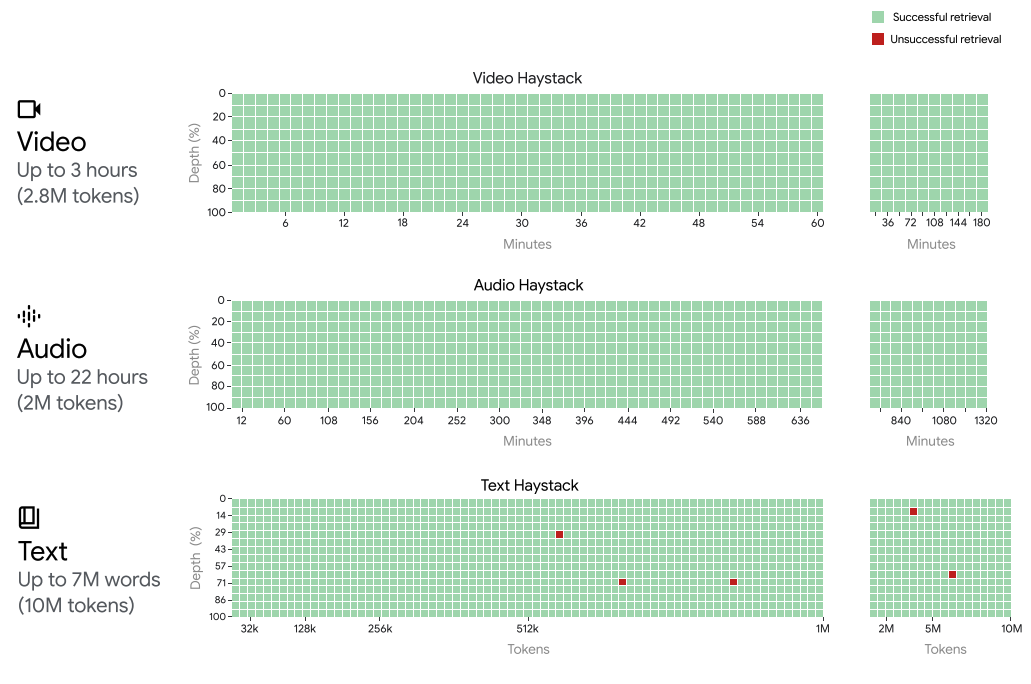
Performanța de recuperare
Gemini 1.5 Pro obține reamintirea aproape perfectă a "acului" de până la 1 milion de tokeni în toate modalitățile (text, video și audio).
Capacitățile ferestrei de context
Gemini 1.5 Pro poate procesa și menține performanța de recuperare când se extinde la:
- ~22 ore de înregistrări
- 10 x 1440 pagini de carte
- Bazele de cod întregi
- 3 ore de video la 1 fps
Performanța pe benchmark-uri
Gemini 1.5 Pro depășește Gemini 1.0 Pro pe majoritatea benchmark-urilor cu performanță semnificativă în:
- Matematică
- Știință
- Raționament
- Multilingvitate
- Înțelegerea video
- Cod
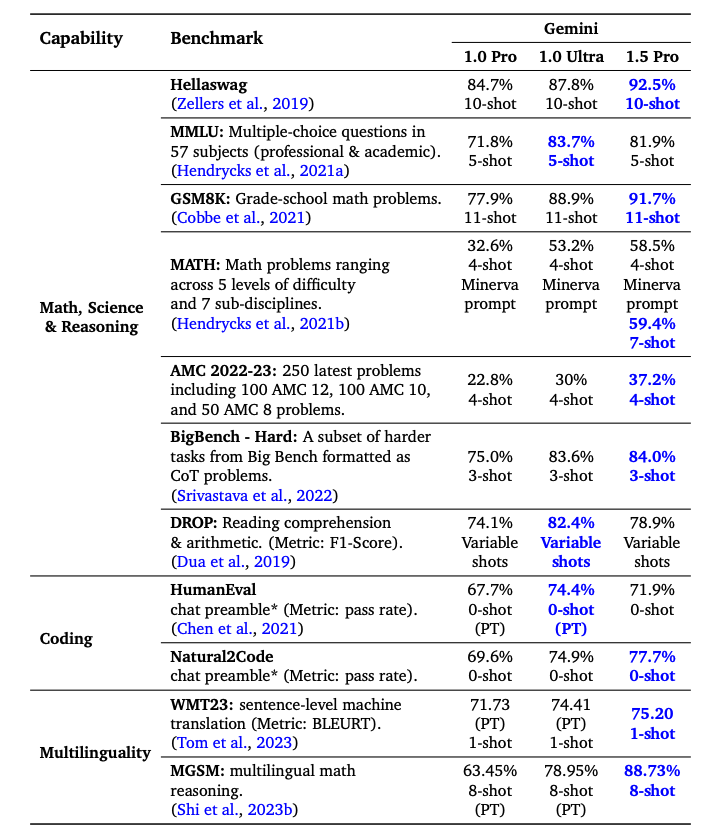
Notă: Gemini 1.5 Pro depășește, de asemenea, Gemini 1.0 Ultra pe jumătate din benchmark-uri în ciuda folosirii semnificativ mai puținei computații de antrenament.
Capacități
Analiza documentelor lungi
Răspunsuri la întrebări de bază
Pentru a demonstra abilitățile Gemini 1.5 Pro de a procesa și analiza documente, începem cu o sarcină foarte de bază de răspuns la întrebări. Modelul Gemini 1.5 Pro din Google AI Studio suportă până la 1 milion de tokeni, deci putem încărca PDF-uri întregi.
Exemplu: Încarcă un PDF și întreabă "Despre ce este lucrarea?"
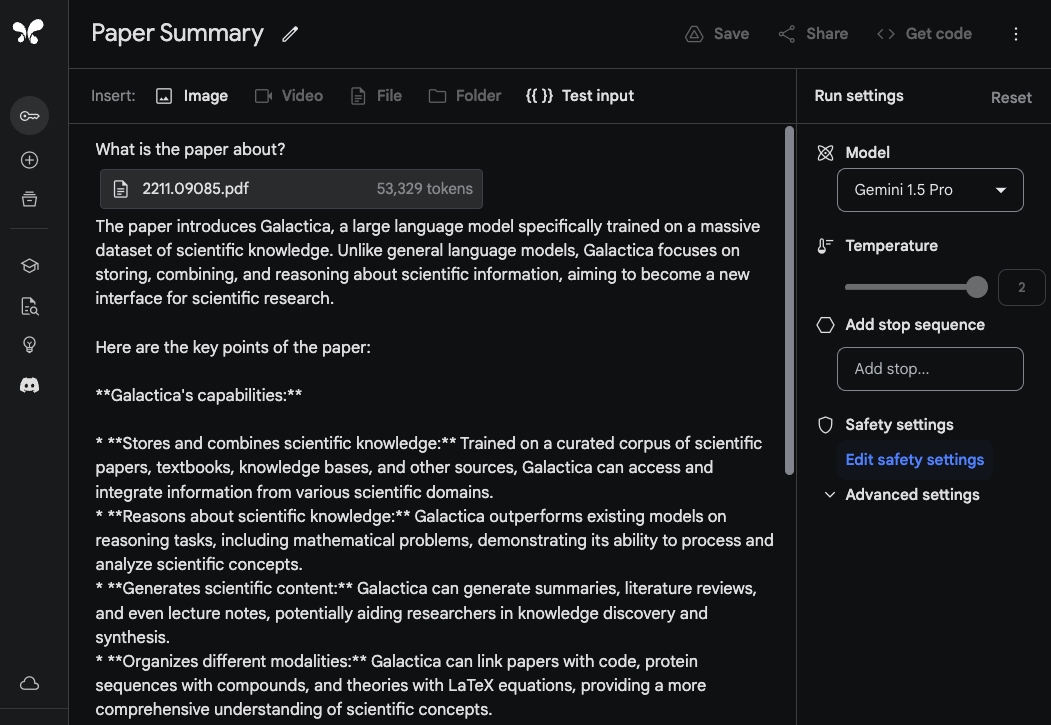
Răspunsul modelului este precis și concis deoarece oferă un rezumat acceptabil al lucrării Galactica.
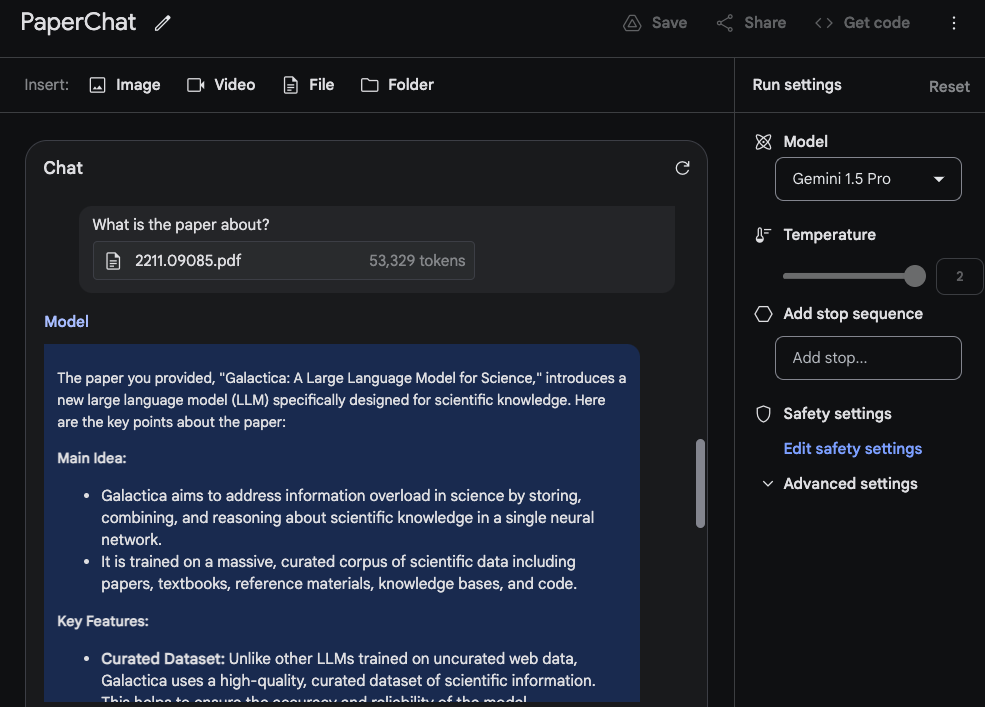
Interacțiunea în format chat
Puteți folosi, de asemenea, formatul de chat pentru a interacționa cu un PDF încărcat. Aceasta este o funcție utilă dacă aveți multe întrebări pe care ați dori să le aveți răspunse din documentul/documentele furnizate.
Analiza cross-document
Pentru a utiliza fereastra de context lungă, să încărcăm acum două PDF-uri și să întrebăm o întrebare care se întinde pe ambele PDF-uri.
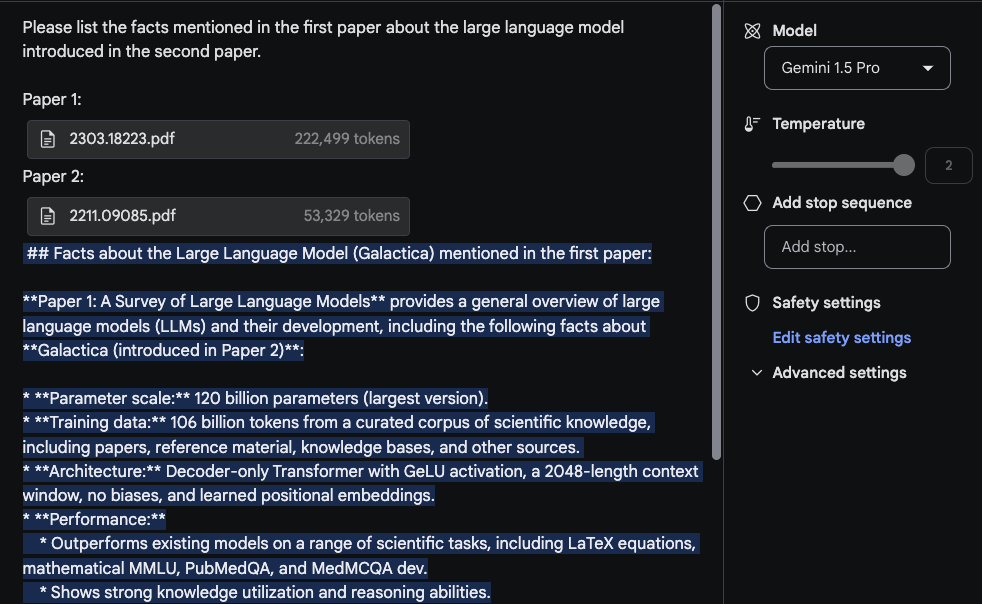
Perspective cheie:
- Informațiile extrase din prima lucrare (sondajul pe LLM-uri) vin dintr-un tabel
- Informațiile despre "Arhitectură" par corecte
- Secțiunea "Performanță" nu aparține acolo (nu a fost găsită în prima lucrare)
Cele mai bune practici:
- Puneți promptul la început
- Etichetați lucrările cu tag-uri (Lucrarea 1, Lucrarea 2)
- Fiți specifici despre ce lucrare să referențiați
Înțelegerea video
Gemini 1.5 Pro este antrenat cu capacități multimodale de la început și demonstrează capacități puternice de înțelegere video.
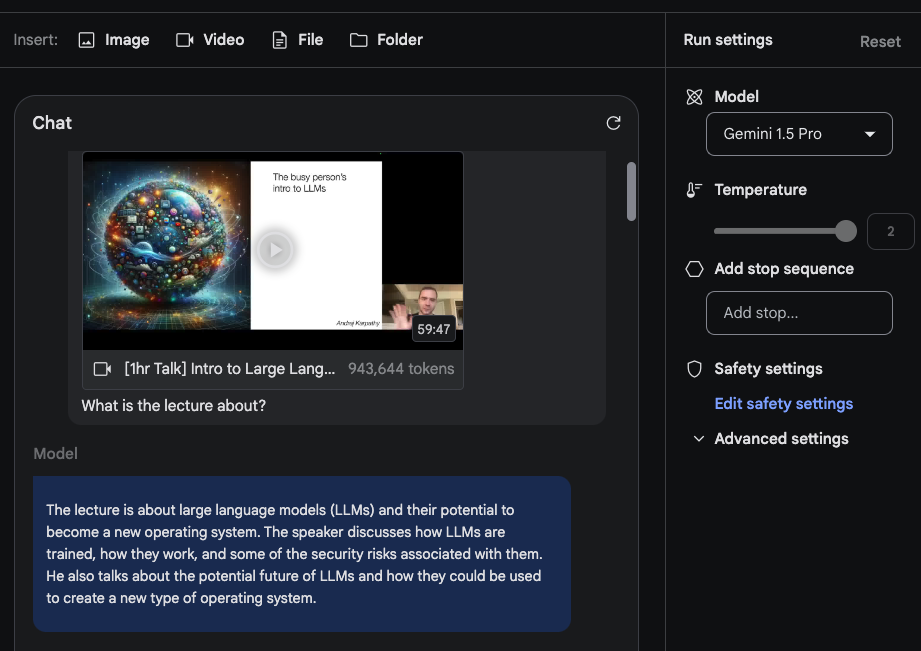
Sumarizarea cursului
Am testat cu cursul recent al lui Andrej Karpathy despre LLM-uri.
Sarcina 1: "Despre ce este cursul?"
- Răspunsul sumarizează cu acuratețe cursul
Sarcina 2: "Furnizați o schiță concisă (lungimea unei pagini) a cursului"
Răspunsul (editat pentru concizie):
Modelele de limbaj mari: Un nou sistem de operare?
Introducerea
- LLM-urile sunt antrenate pe cantități masive de date text și pot genera text de calitate umană
- Ele devin din ce în ce mai puternice și sunt folosite pentru o gamă largă de sarcini
Cum funcționează LLM-urile
- LLM-urile sunt rețele neurale care prezic următorul cuvânt într-o secvență
- Ele învață prin ajustarea iterativă a parametrilor lor pentru a face predicții mai bune
- Deși putem măsura performanța lor, nu înțelegem pe deplin cum colaborează miliardele de parametri
Antrenarea LLM-urilor
- Necesită cantități masive de date și putere de calcul
- Poate fi gândit ca "comprimarea internetului" într-un singur fișier
- De exemplu, antrenarea LLaMA 2 70B a necesitat 6.000 de GPU-uri timp de 12 zile și a costat ~2 milioane de dolari
Securitatea LLM-urilor
- Securitatea LLM este un domeniu nou și în evoluție rapidă
- Riscurile cheie de securitate includ jailbreaking, injecția de prompturi și otrăvirea datelor
Extragerea detaliilor specifice
Exemplu: "Care sunt FLOP-urile raportate pentru Llama 2 în curs?"
Răspuns: "Cursul raportează că antrenarea Llama 2 70B a necesitat aproximativ 1 trilion de FLOP-uri."
Notă: Aceasta nu este precisă. Răspunsul corect ar trebui să fie ~1e24 FLOP-uri. Raportul tehnic conține multe instanțe unde aceste modele cu context lung eșuează când sunt întrebate despre întrebări specifice despre video.
Extragerea informațiilor din tabele
Modelul poate extrage informații din tabele din video, deși cu unele inconsistențe:
- Coloanele tabelelor sunt în general corecte
- Etichetele rândurilor pot avea erori (de ex., "Concept Resolution" ar trebui să fie "Coref Resolution")
- Inconsistențe similare observate în diferite sarcini de extragere
Recuperarea timestamp-urilor și scenei
Exemplul 1: "La ce timestamp începe secțiunea LLM OS?" Răspuns: "Secțiunea LLM OS începe la 42:17." ✓ Corect
Exemplul 2: "Poți să explici graficul (din partea dreaptă) de pe slide-ul de auto-îmbunătățire?"
Răspuns: Modelul oferă o explicație detaliată a graficului de performanță AlphaGo Zero, făcând o utilizare bună a informațiilor vizuale furnizate.

Raționamentul codului
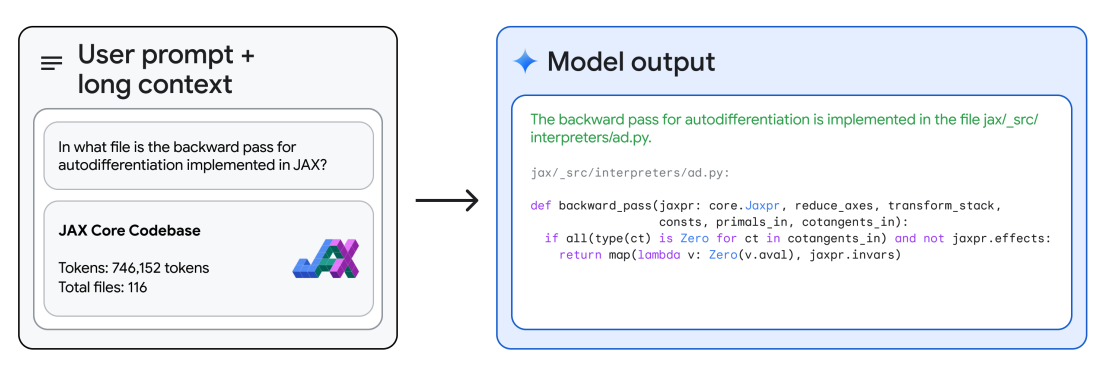
Cu raționamentul său cu context lung, Gemini 1.5 Pro poate răspunde la întrebări despre bazele de cod întregi. Folosind Google AI Studio, puteți încărca o bază de cod întreagă și să o promptați cu diferite întrebări sau sarcini legate de cod.
Exemplu: Raportul tehnic arată modelul dat întregii baze de cod JAX (~746K tokeni) și întrebat să identifice locația unei metode core de diferențiere automată.
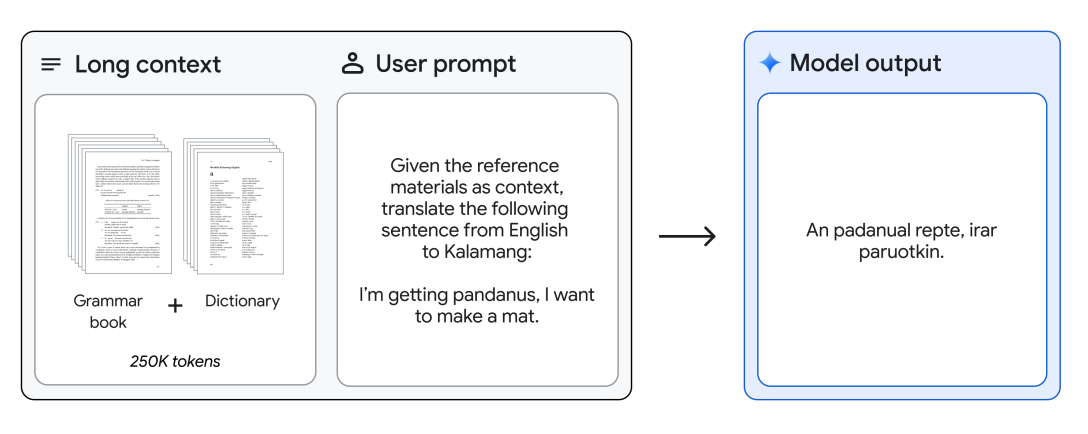
Traducerea din engleză în Kalamang
Gemini 1.5 Pro poate fi furnizat un manual de gramatică (500 de pagini de documentație lingvistică, un dicționar și ~400 de propoziții paralele) pentru Kalamang, o limbă vorbită de mai puțin de 200 de vorbitori în întreaga lume, și traduce din engleză în Kalamang la nivelul unei persoane care învață din același conținut.
Aceasta demonstrează abilitățile de învățare în context ale Gemini 1.5 Pro activate prin contextul lung.
Învățăminte cheie
- Fereastra de context revoluționară: Capacitatea de 1M-10M tokeni deblochează cazuri de utilizare noi
- Excelența multimodală: Performanță puternică pe text, video, audio și cod
- Arhitectura eficientă: Designul MoE oferă performanță mai bună cu mai puțină computație
- Înțelegerea formei lungi: Poate procesa cărți întregi, baze de cod și ore de media
- Raționamentul cross-document: Abilitatea de a analiza relațiile între multiple surse
- Inteligența video: Înțelegerea sofisticată a conținutului vizual și informațiilor temporale
Referințe
- Gemini 1.5: Deblocarea înțelegerii multimodale pe milioane de tokeni de context
- Gemini 1.5: Următorul nostru model de generație, acum disponibil pentru Preview Privat în Google AI Studio