
Llama 3
Overview
Meta recently introduced their new family of large language models (LLMs) called Llama 3. This release includes 8B and 70B parameters pre-trained and instruction-tuned models.
Llama 3 Architecture Details
Here is a summary of the mentioned technical details of Llama 3:
Core Architecture
- Type: Standard decoder-only transformer
- Vocabulary: 128K tokens
- Sequence length: 8K tokens
- Attention mechanism: Grouped query attention (GQA)
Training Details
- Pretraining: Over 15T tokens
- Post-training: Combination of SFT, rejection sampling, PPO, and DPO
Performance
Model Comparisons
Llama 3 8B
Llama 3 8B (instruction-tuned) outperforms:
- Gemma 7B
- Mistral 7B Instruct
Llama 3 70B
Llama 3 70B broadly outperforms:
- Gemini Pro 1.5
- Claude 3 Sonnet
Note: Falls slightly behind on the MATH benchmark when compared to Gemini Pro 1.5.
Benchmark Results
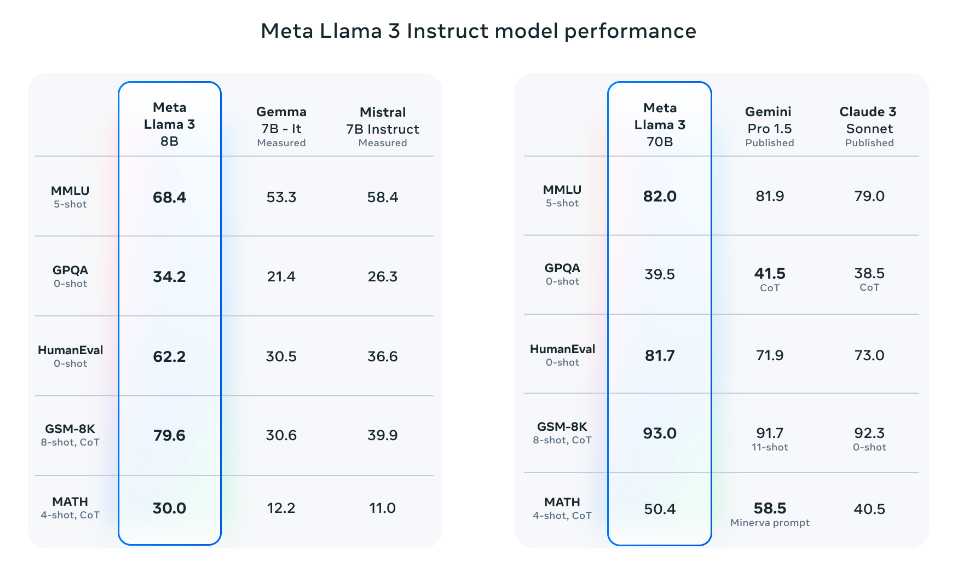
Source: Meta AI
Pretrained Model Performance
The pretrained models also outperform other models on several benchmarks:
- AGIEval (English)
- MMLU
- Big-Bench Hard
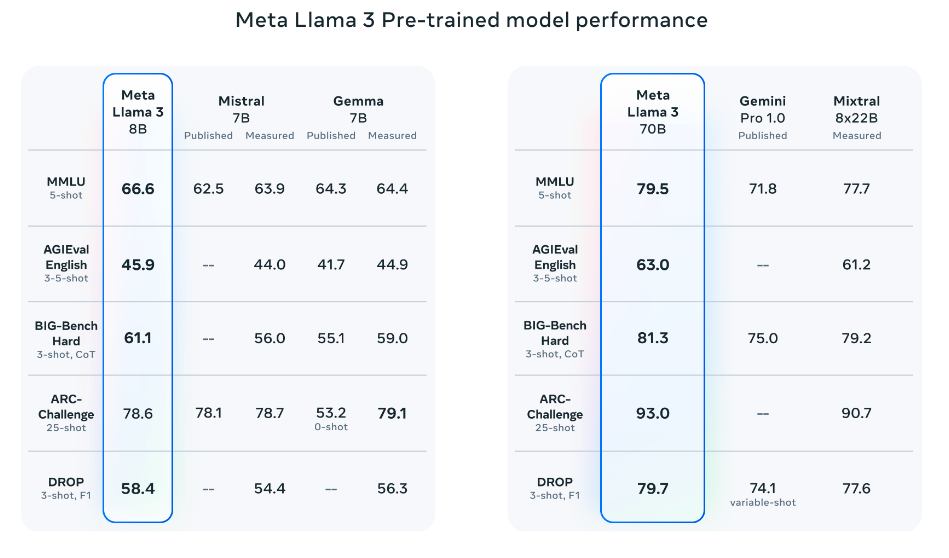
Source: Meta AI
Llama 3 400B
Upcoming Release
Meta also reported that they will be releasing a 400B parameter model which is still training and coming soon!
Planned Features
There are also efforts around:
- Multimodal support
- Multilingual capabilities
- Longer context windows
Current Performance
The current checkpoint for Llama 3 400B (as of April 15, 2024) produces the following results on common benchmarks like MMLU and Big-Bench Hard:
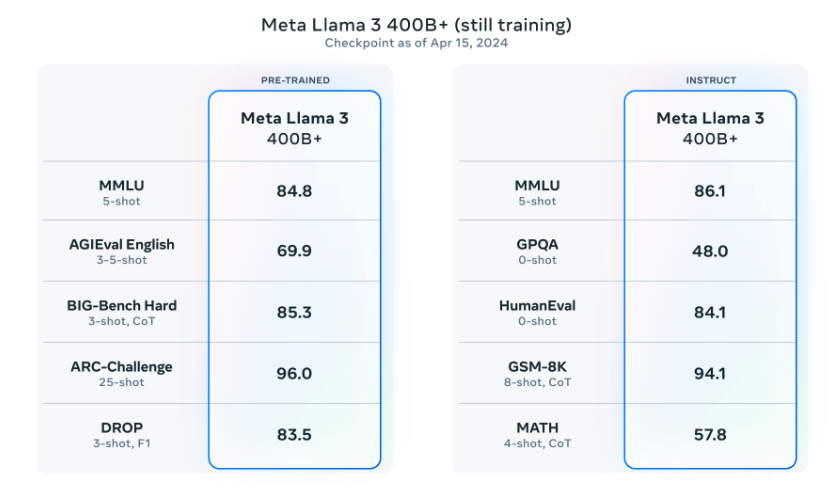
Source: Meta AI
Licensing
The licensing information for the Llama 3 models can be found on the model card.
Extended Review of Llama 3
Here is a longer review of Llama 3:
[Extended review content would go here]
Key Takeaways
- Dual Model Release: 8B and 70B parameter variants available
- Strong Performance: Outperforms Gemma 7B, Mistral 7B Instruct, and competes with Gemini Pro 1.5
- Advanced Architecture: Uses grouped query attention and extensive post-training techniques
- Massive Scale: 400B parameter model in development
- Future Capabilities: Multimodal, multilingual, and extended context planned
- Open Access: Available for research and development use