
Grok-1
Overview
Grok-1 is a mixture-of-experts (MoE) large language model (LLM) with 314B parameters which includes the open release of the base model weights and network architecture.
Model Details
Architecture
- Type: Mixture-of-experts (MoE) large language model
- Parameters: 314B total parameters
- Activation: 25% of weights activated for a given token at inference time
- Training: Developed by xAI
Training Information
- Pretraining cutoff date: October 2023
- Status: Raw base model checkpoint from pre-training phase
- Fine-tuning: Not fine-tuned for specific applications like conversational agents
Licensing
The model has been released under the Apache 2.0 license.
Results and Capabilities
Benchmark Performance
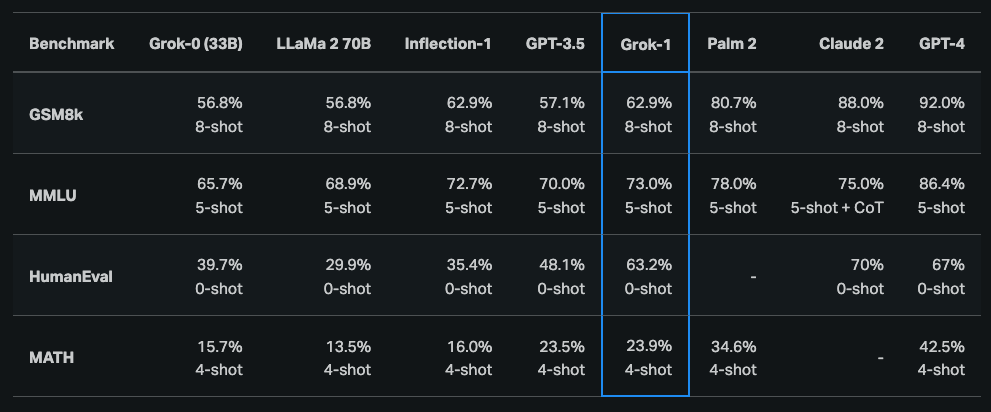
According to the initial announcement, Grok-1 demonstrated strong capabilities across reasoning and coding tasks:
- HumanEval coding task: 63.2%
- MMLU: 73%
Model Comparison
Grok-1 generally outperforms:
- ChatGPT-3.5
- Inflection-1
But still falls behind improved models like GPT-4.
Benchmark Results
Academic Performance
Grok-1 was also reported to score a C (59%) compared to a B (68%) from GPT-4 on the Hungarian national high school finals in mathematics.

Access and Usage
Model Repository
Check out the model here: https://github.com/xai-org/grok-1
Hardware Requirements
Due to the size of Grok-1 (314B parameters), xAI recommends a multi-GPU machine to test the model.
Key Takeaways
- Massive Scale: 314B parameter MoE architecture
- Open Source: Apache 2.0 licensed with open weights and architecture
- Strong Performance: Outperforms ChatGPT-3.5 and Inflection-1
- Competitive Results: 63.2% on HumanEval, 73% on MMLU
- Academic Capability: Competes with GPT-4 on mathematical tasks
- Resource Intensive: Requires multi-GPU setup for testing